 MySQL索引基本原理
MySQL索引基本原理
# MySQL 索引基本原理
# 什么是索引?
索引是帮助MySQL高效获取数据是 排好序 的 数据结构
# 索引的数据结构
- 二叉树,红黑树,B-tree
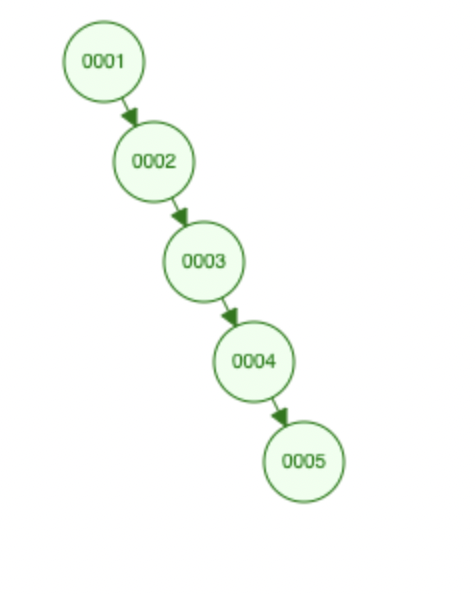
这是二叉树,在这种情况下也是一个链表,每次查找都是一次I/O查找,效率很慢,特别在数据依次递增的情况下,意义不大,所以不作为MySQL存储结构
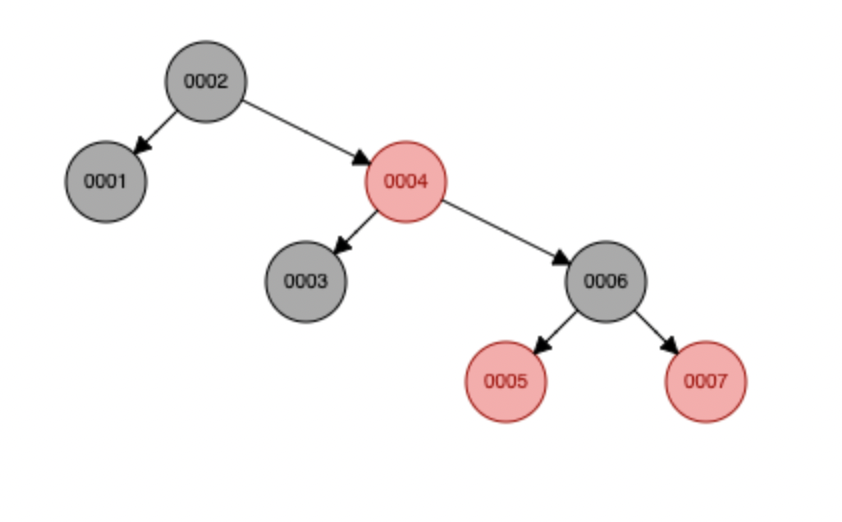
这是红黑树,也是二叉平衡树,JDK1.8 hashmap底层就是红黑树实现的 MySQL为什么不用红黑树,因为数据库会存储大量数据,会导致树太高了,极端情况下,索引在叶子节点,那就要遍历很深了
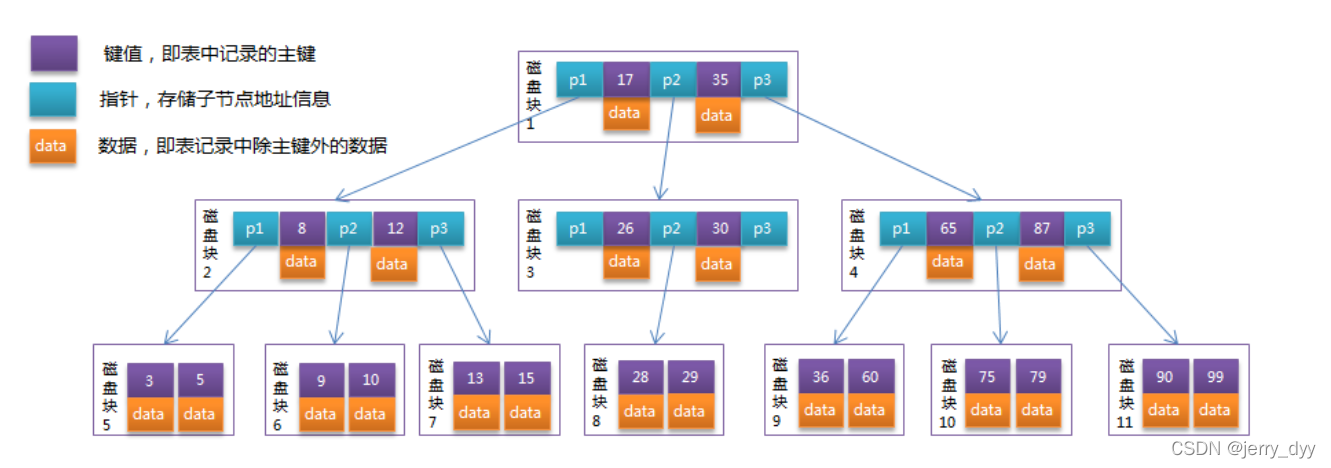
Btree在红黑树上支持节点索引横向扩展,可以很好的控制树的高度,但MySQL依然还不是用Btree作为存储数据结构
上图中的每走一次箭头,都意味着一次磁盘随机IO,意味着磁臂去寻址,很慢。
每一个节点,意味着一个页空间,一个页空间默认大小为16KB,可设置。
B-Tree就是为了磁盘等外设存储设备的机理设计的一种平衡查找树,利用了磁盘块空间,把磁盘块空间充分利用,多存储几个键值、指针,通过这样的方式,可以减少树的深度,也就意味着减少磁盘的随机IO次数,加快访问速度。
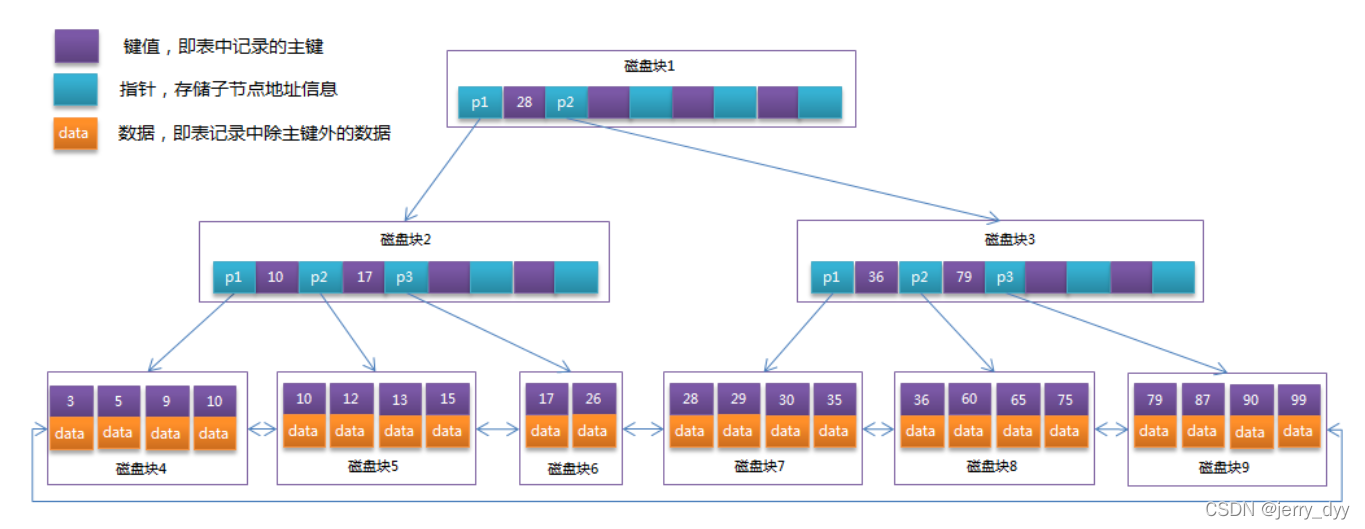
在B-Tree的基础上优化了:
1、节点上只存储键值,不存储数据,这样一来,在有限的节点空间(页空间)内就可以存放更多的键值、指针;
2、所有数据都放在叶子节点中,所有叶子节点之间有链指针(双向循环列表),便于范围查找,也便于排序。
算一下一颗高度为3的B+tree可以放多少数据?
P指针,存放的是下一个节点的地址,占6B,假设索引为bigint,占8B,那么证个节点可以放16kb/(6+8)B 大概等于1170个索引,那么 1170 * 1170 * 16 可以放2000多万个索引了
# MyISAM和InnoDB存储引擎基本原理
MyISAM存储引擎分为3个文件,.frm存放数据结构,.MYD存放数据,.MYI存放索引 查找的过程是:先从B+Tree二分查找到对应的叶子节点(叶子节点存放数据页的地址),然后找到叶子节点的数据地址,再去.MYD数据文件找到对应的数据(非聚集)
Innodb存储引擎分为2个文件,.frm存放数据结构,.ibd存放数据和索引,叶子节点存放索引,还有索引所在行的其他列数据,这是与MyISAM最大区别(聚集索引),如果非主键索引,会找到叶子节点,找到主键索引,然后再拿到主键再回表查询
# Mysql为不用hash作为存储数据结构??
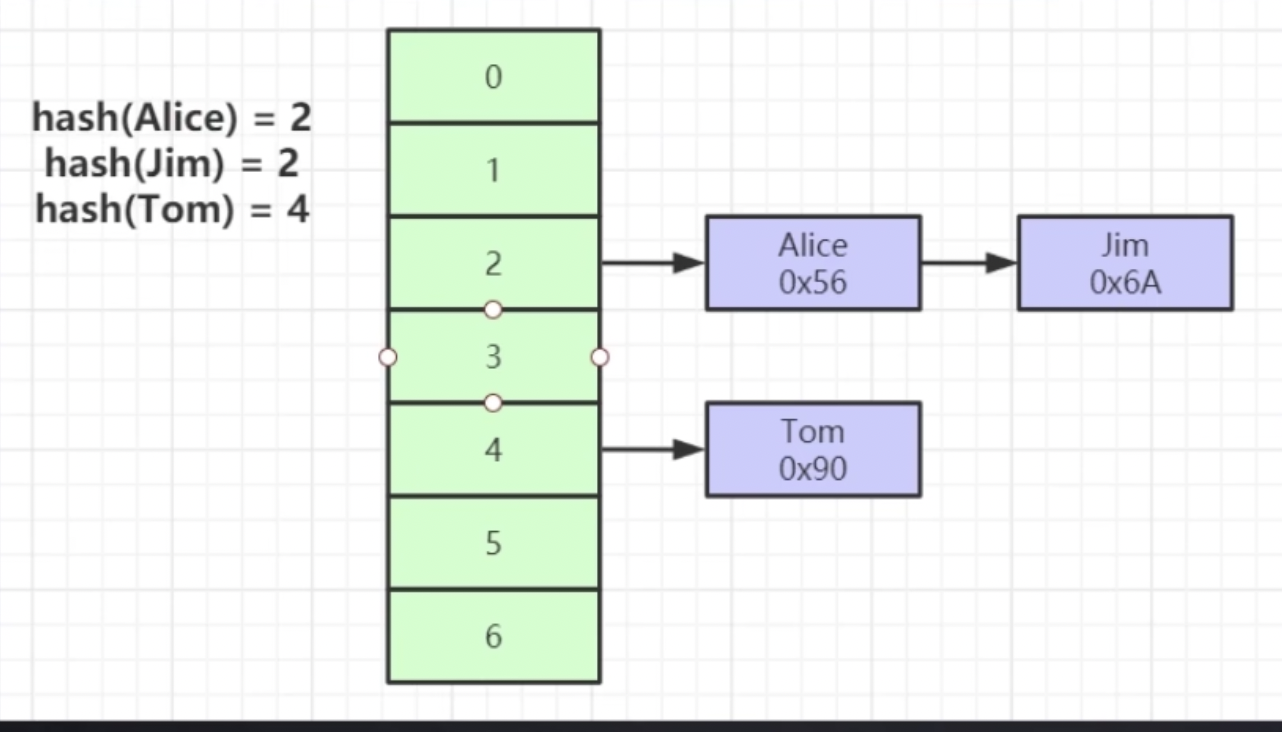
hash的时间复杂度为o(1),常量基本,效率相当非常高,对索引key一次性hash计算就可以定位到数据,但仅只能满足“=”,“in”,不支持范围查询,还有一个问题就是hash冲突问题
# 主键设置为自增?
- 保证页的连续性,提高性能 如果不设置自增,假如再中间新插入一个数据,那这个节点可能就要断页,有可能还要调整与父节点结构,很麻烦,效率很低