 Kafka并发原理
Kafka并发原理
# 基础网络并发原型
在高性能网络编程领域,有一个非常著名的模式——Reactor模式。这种模式非常适合多个客户端并发向服务器发送数据请求的场景。用大神Doug Lea描述的一幅架构图说明:
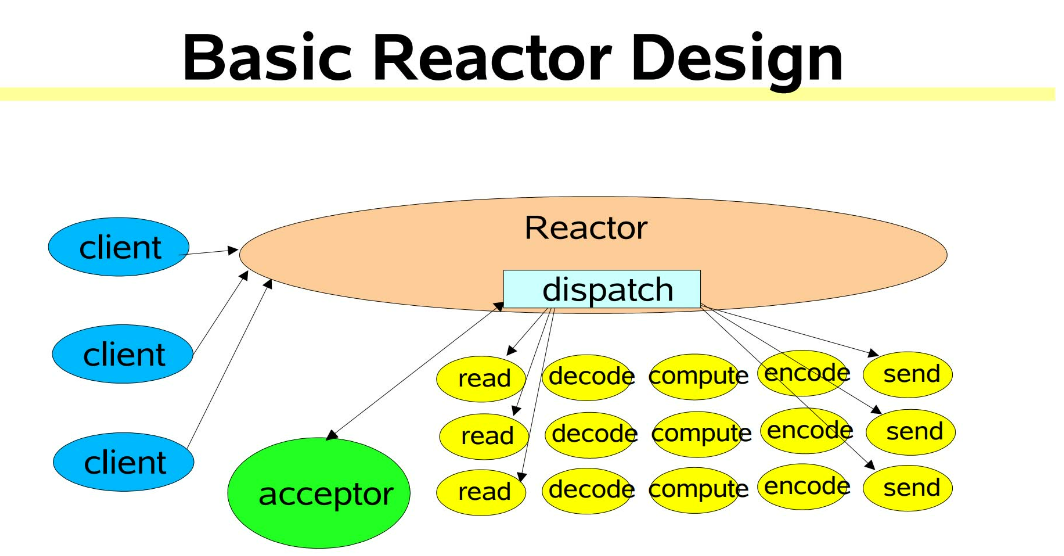
- Reactor模式是基于事件驱动
- 多个客户端会发送请求给到 Reactor。Reactor 有个请求分发线程
- Dispatcher,也就是图中的绿色的 Acceptor,它会将不同的请求下分发到多个工作线程中处理。
- Acceptor非常轻量级,所以非常高的吞吐量
# kafka超高网络并发模型
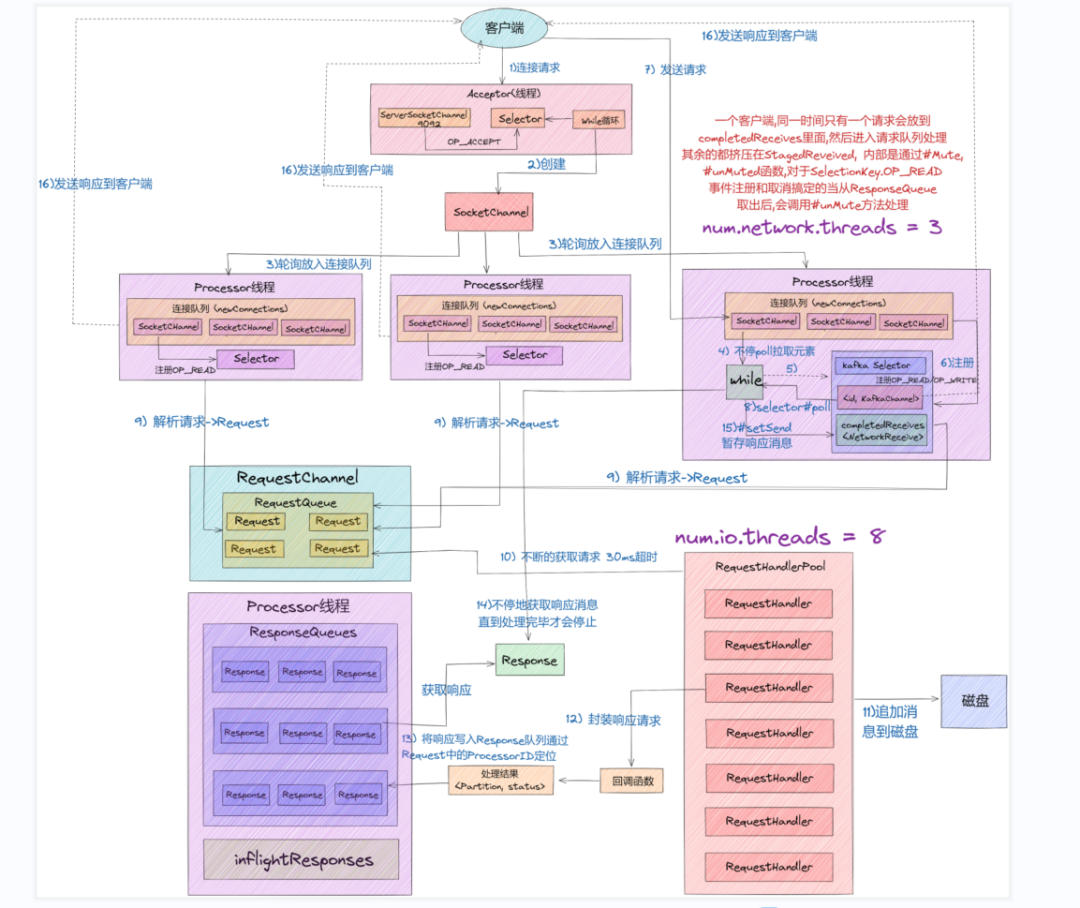
- 从上图中我们可以看出,Kafka 网络通信架构中用到的组件主要由两大部分构成:SocketServer 和 RequestHandlerPool。
- SocketServer 组件是 Kafka 超高并发网络通信层中最重要的子模块。它包含 Acceptor 线程、Processor 线程和 RequestChannel 等对象,都是网络通信的重要组成部分。它主要实现了 Reactor 设计模式,主要用来处理外部多个 Clients(这里的 Clients 可能包含 Producer、Consumer 或其他 Broker)的并发请求,并负责将处理结果封装进 Response 中,返还给 Clients。
- RequestHandlerPool 组件就是我们常说的 I/O 工作线程池,里面定义了若干个 I/O 线程,主要用来执行真实的请求处理逻辑。
- 这里注意的是:跟 RequestHandler 相比, 上面所说的Acceptor、Processor 线程 还有 RequestChannel 等都不做请求处理, 它们只是请求和响应的「搬运工」。
# kafka写流程
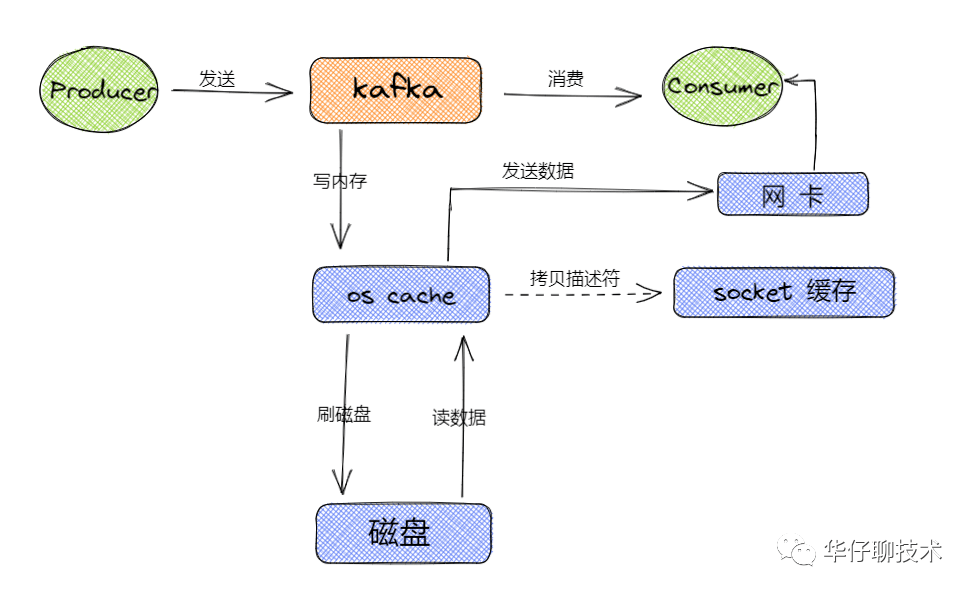 从上图可以得出 Kafka 读写数据的流程主要都是基于os cache,所以基本上 Kafka 都是基于内存来进行数据流转的,这样的话要分配尽可能多的内存资源给os cache。
从上图可以得出 Kafka 读写数据的流程主要都是基于os cache,所以基本上 Kafka 都是基于内存来进行数据流转的,这样的话要分配尽可能多的内存资源给os cache。
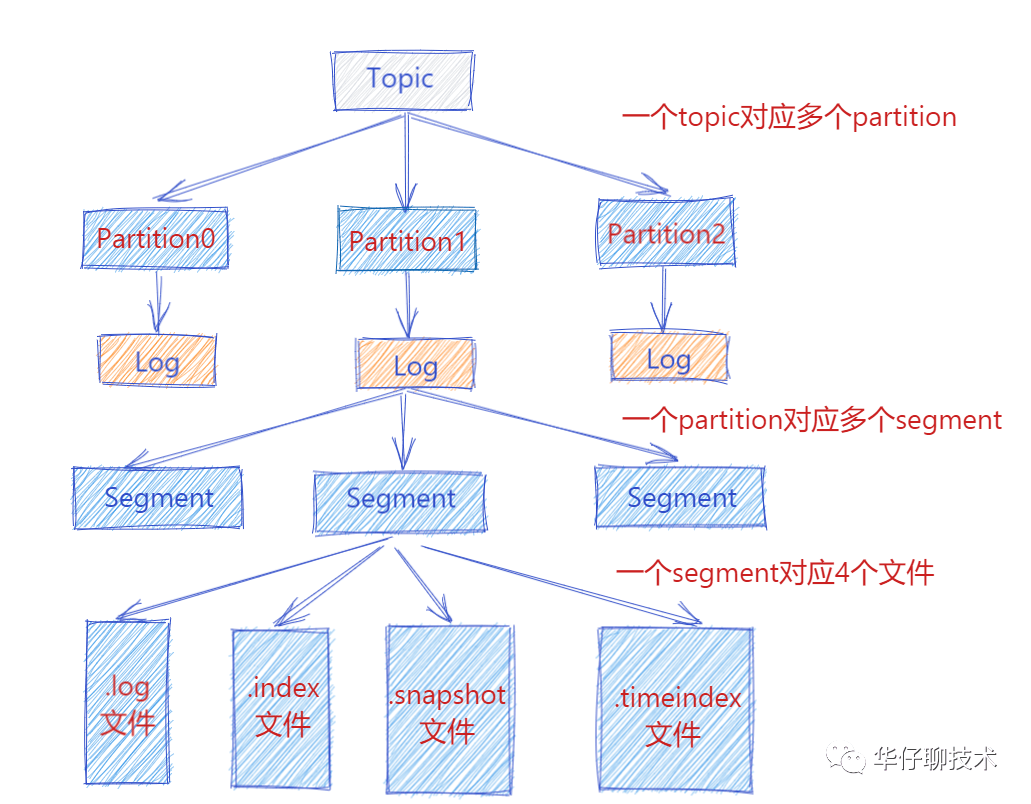 从上图可以看出一个 Topic 会对于多个 partition,一个 partition 会对应多个 segment ,一个 segment 会对应磁盘上4个log文件。假设我们这个平台总共100个 Topic ,那么总共有 100 Topic * 5 partition * 3 副本 = 1500 partition 。对于 partition 来说实际上就是物理机上一个文件目录, .log就是存储数据文件的,默认情况下一个.log日志文件大小为1G。
从上图可以看出一个 Topic 会对于多个 partition,一个 partition 会对应多个 segment ,一个 segment 会对应磁盘上4个log文件。假设我们这个平台总共100个 Topic ,那么总共有 100 Topic * 5 partition * 3 副本 = 1500 partition 。对于 partition 来说实际上就是物理机上一个文件目录, .log就是存储数据文件的,默认情况下一个.log日志文件大小为1G。
如果要保证这1500个 partition 的最新的 .log 文件的数据都在内存中,这样性能当然是最好的,需要 1500 * 1G = 1500 G内存,但是我们没有必要所有的数据都驻留到内存中,我们只保证25%左右的数据在内存中就可以了,这样大概需要 1500 * 250M = 1500 * 0.25G = 375G内存
# kafka高可用
可以用zookeeper做高可用调度,目前zookeeper已经和kafka分开了,不再把元数据到zookeeper配置一遍
# kafka ISR机制
这个机制会自动给每个Partition维护一个ISR列表,这个列表里一定会有Leader,然后还会包含跟Leader保持同步的Follower。
也就是说,只要Leader的某个Follower一直跟他保持数据同步,那么就会存在于ISR列表里。
但是如果Follower因为自身发生一些问题,导致不能及时的从Leader同步数据过去,那么这个Follower就会被认为是“out-of-sync”,从ISR列表里踢出去。
说白了,就是Kafka自动维护和监控哪些Follower及时的跟上了Leader的数据同步。
# kafka如何保证数据不丢失
- 每个Partition都至少得有1个Follower在ISR列表里,跟上了Leader的数据同步
- 每次写入数据的时候,都要求至少写入Partition Leader成功,同时还有至少一个ISR里的Follower也写入成功,才算这个写入是成功了
如果不满足上述两个条件,那就一直写入失败,让生产系统不停的尝试重试,直到满足上述两个条件,然后才能认为写入成功 按照上述思路去配置相应的参数,才能保证写入Kafka的数据不会丢失
# 调优
- 客户端和服务端版本要一致
- 参数调优
num.network.threads 创建 Processor 处理网络请求线程个数,建议设置为 Broker 当前CPU核心数*2,这个值太低经常出现网络空闲太低而缺失副本。
num.io.threads 创建 KafkaRequestHandler 处理具体请求线程个数,建议设置为Broker磁盘个数*2。
num.replica.fetchers 建议设置为CPU核心数/4,适当提高可以提升CPU利用率及 Follower同步 Leader 数据当并行度。
compression.type 建议采用lz4压缩类型,压缩可以提升CPU利用率同时可以减少网络传输数据量。
queued.max.requests 在网络线程停止读取新请求之前,可以排队等待I/O线程处理的最大请求个数,生产环境建议配置最少500以上,默认500。
log.flush.xxx log.flush.scheduler.interval.ms
log.flush.interval.ms
log.flush.interval.messages
这几个参数表示日志数据刷新到磁盘的策略,应该保持默认配置,刷盘策略让操作系统去完成,由操作系统来决定什么时候把数据刷盘;如果设置来这个参数,可能对吞吐量影响非常大。
auto.leader.rebalance.enable 表示是否开启leader自动负载均衡,默认true;我们应该把这个参数设置为false,因为自动负载均衡不可控,可能影响集群性能和稳定。
- kafka是顺序写,都是追加到文件的末尾,用机械盘即可,如果可以的话,当然SSD
- kafka底层是运行在JVM虚拟机上,需要设置JVM内存大小
- 设置key,相同的key写到同一个partition
- 数据传输的零拷贝,kafka底层通过操作系统sendfile来实现零拷贝
- 减少两次内核与用户空间的数据拷贝
- 减少内核与用户空间上下文切换