 人工智能总览
人工智能总览
# AI总体架构
2024年是人工智能的元年,从openAI的chatGPT问世后,人工智能如火如荼,很多开源的产品大模型的出现;到2025年人工智能越来越成熟了,也很多产品落地了
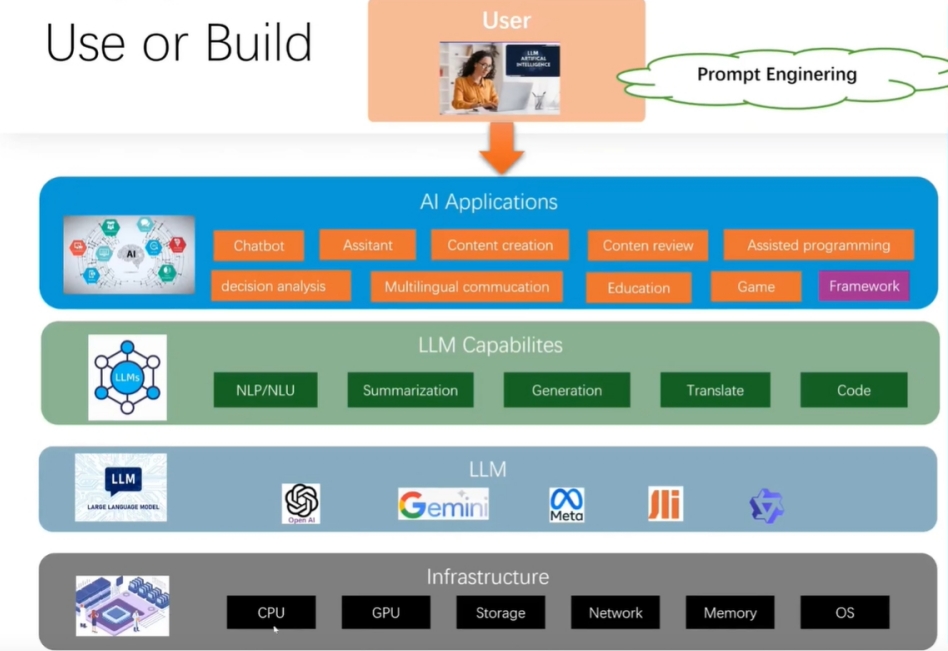
人工智能在企业的产品架构如上图所示
- 第一层就是企业的产品应用
- 第二层是各大模型为产品提供的各大能力
- 第三层是业内各大模型的,如阿里的Qwen,谷歌的Gemini,Meta的Llama,openAI的chatGPT等等都是非常不错的大模型
- 第四层则是企业的基础架构,数据库,操作系统,存储,GPU等等
# 业内知名的大模型网站
- 国外的Hugging Face
- 国内阿里的ModelScope
只要可以下载的模型,基本上都是可以商用
# AI技术体系
- AI大模型的基础能力
- Prompt提示词工程
- RAG检索增强生成
- LlamaIndex & LangChain框架
- Dify && Coze 平台应用
- LangGraph 构建多模态AI系统
# AI 三大学习方法
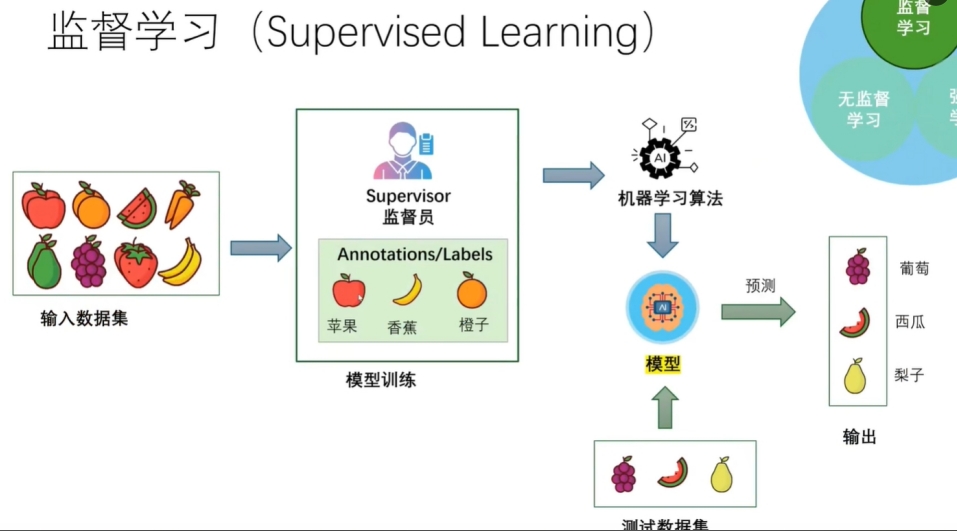
- 监督学习方法,基本上是最原始的方法,数据集需要监督员去打标签,然后进行模型训练,最后输出大模型
这方法有2个问题:
- 第一个问题是需要大量的人力,可能至少要上千人
- 第二个问题是有些数据是很难去给定义或者打标签的
- 无监督学习
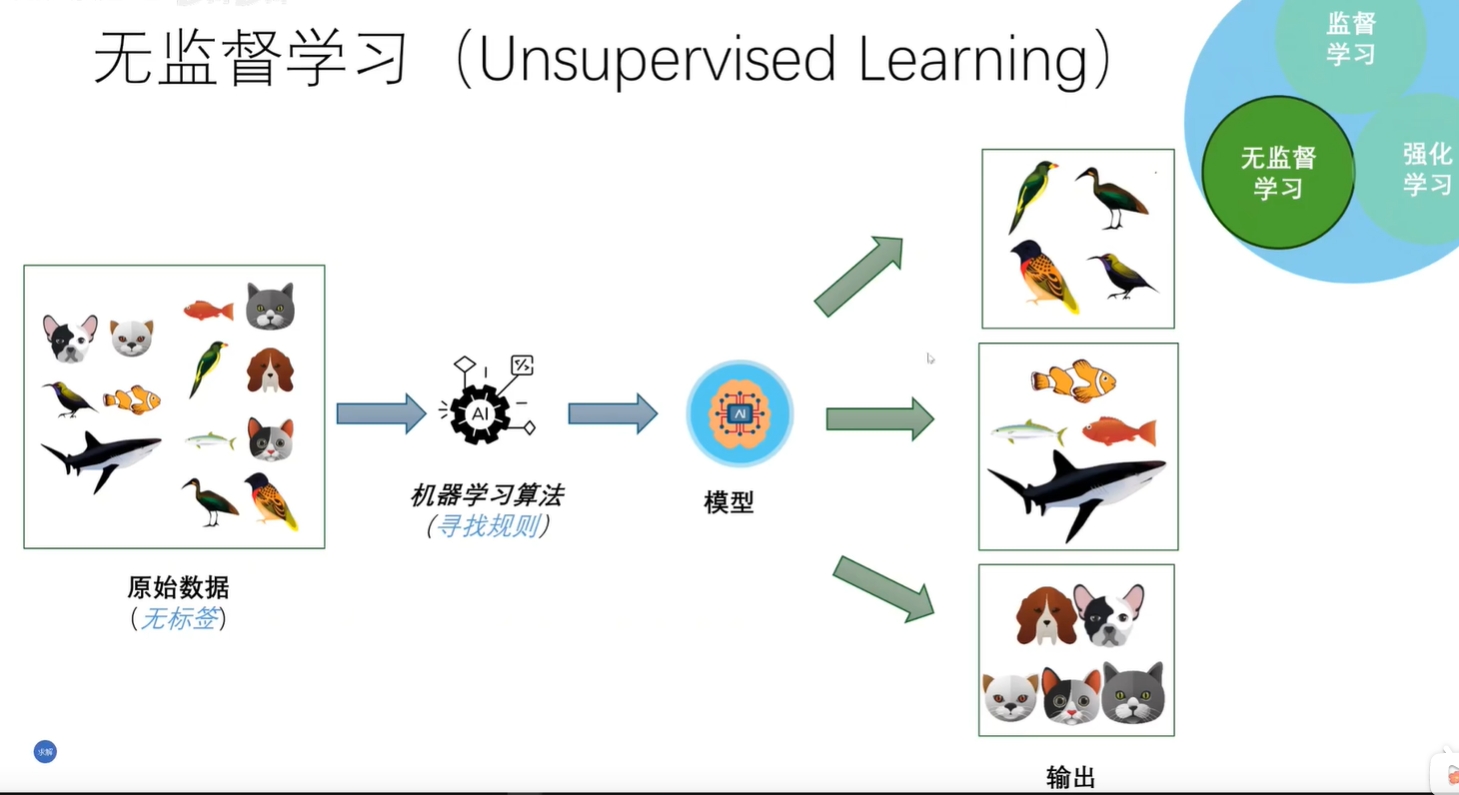
这方法,用机器学习代替人打标签
- 强化学习
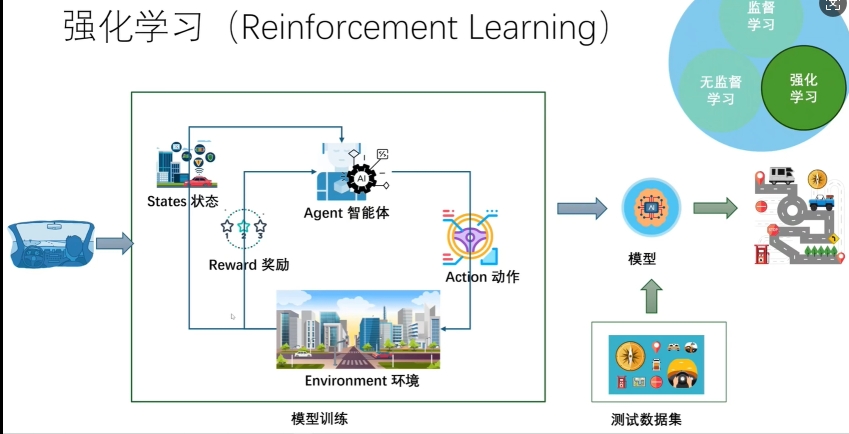
这方法,主要是通过这个奖励,然后反馈给智能体agent,然后不断强化大模型
# RLHF 架构
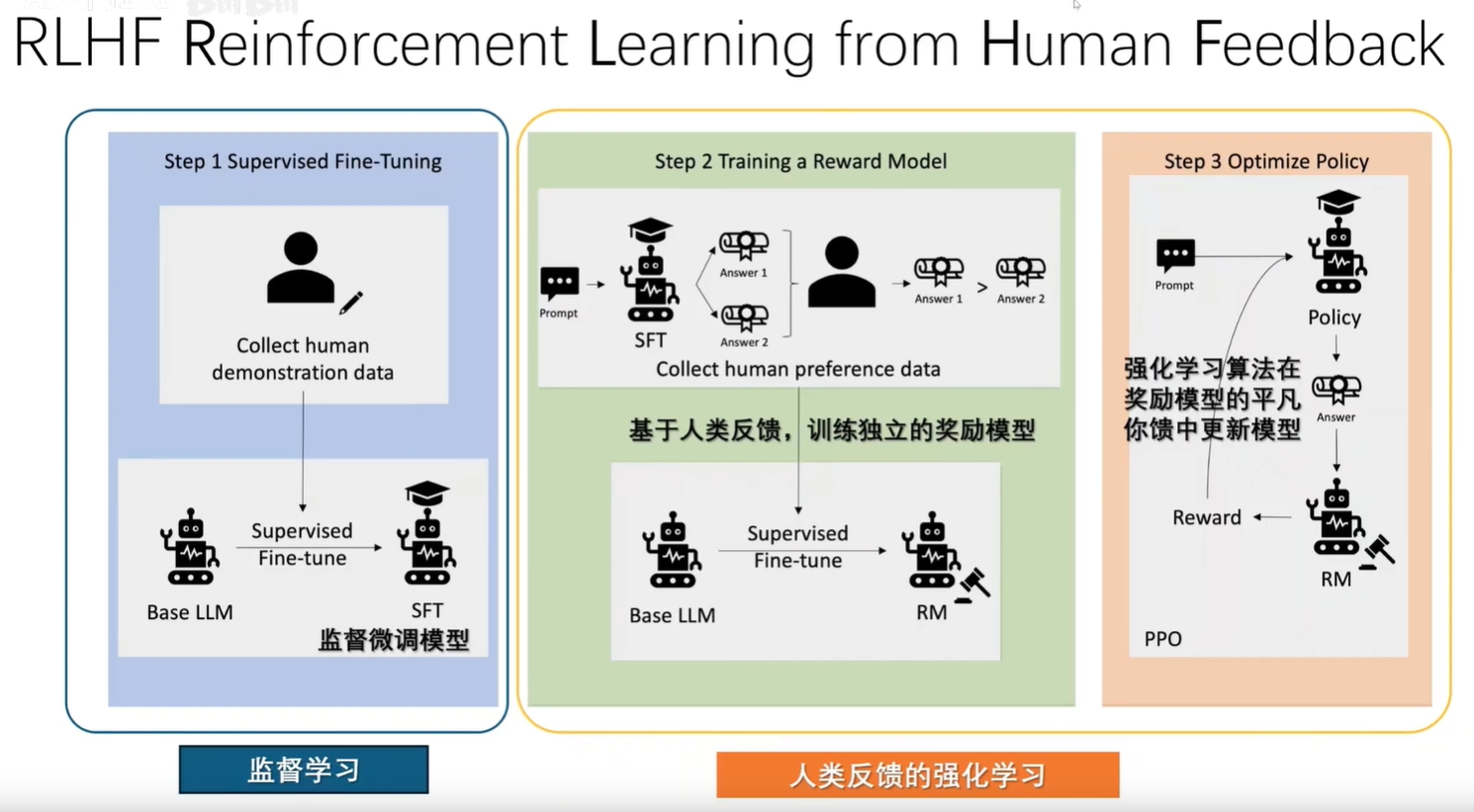
流程:
- 第一步:人通过收集数据,然后打标签,微调训练出一个初模型
- 第二步:人通过问答,然后对答案进行评分,然后基于反馈训练出独立的奖励模型
- 第三步:通过机器学习不断强化模型
openAI的ChatGPT基本上也是经过这几个阶段训练出来的大模型
# Transformer
![]()
2017年 Google发表论文《Attention is all you need》提出了全新的简单网络架构 Transformer,它完全基于自注意力机制来处理输入序列的依赖关系,摒弃了循环和卷积操作。
从 片段记忆 到 全局记忆
从 串行处理 到 高效并行
# RAG 架构
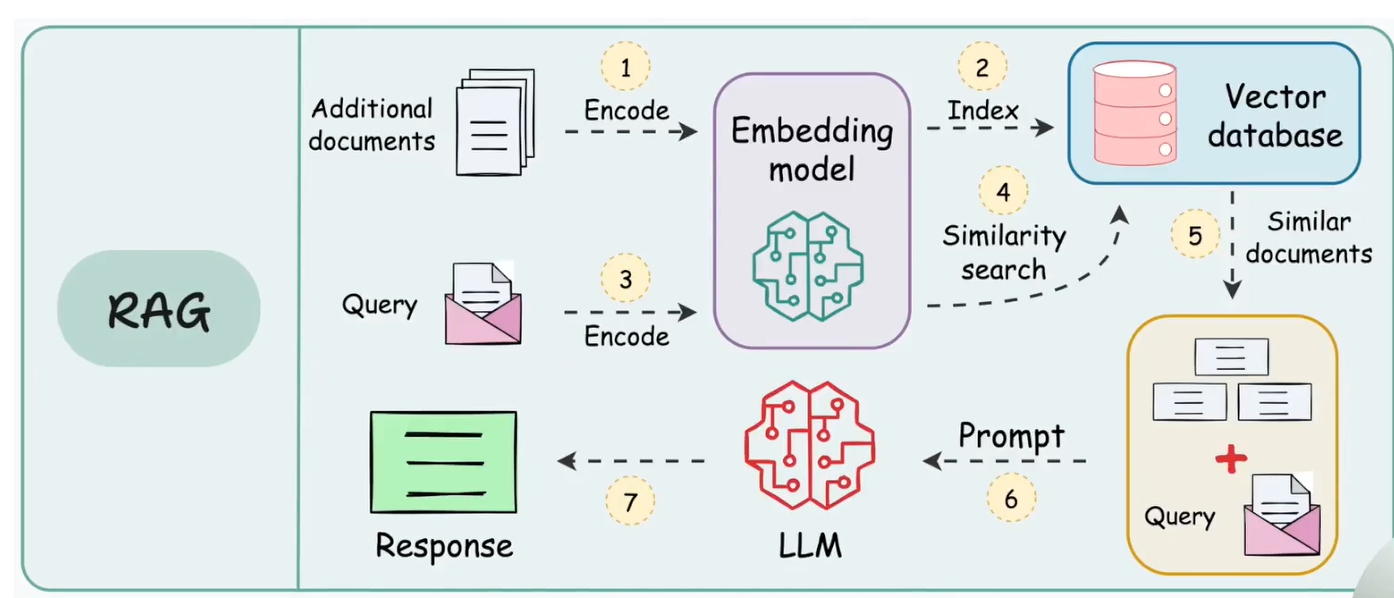
- 第一阶段:把企业的私有数据(txt,pdf,db等)做成一个向量模型,然后存储到向量数据库
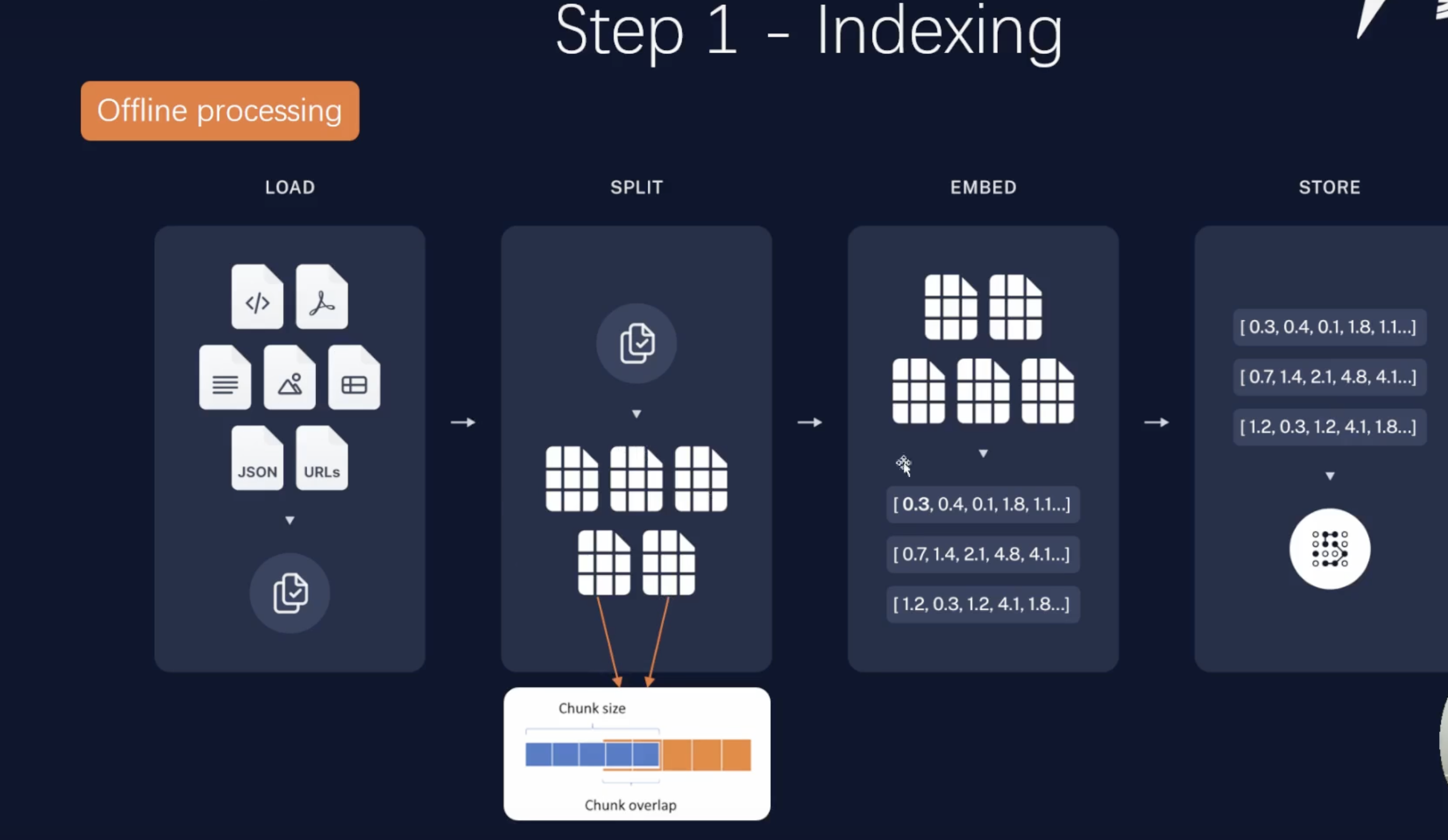
这里的难点就是文档的切分,切得好,准确率高;切不好,容易出现幻觉
- 第二阶段:把问题通过向量模型转成向量,再到向量数据库找对应的相似文档,然后通过提示词,到语言大模型,找出答案,返回

这里的难点是检索,进行重排序,影响到召回率
# 文本生成模型
- Qwen2.5 很优秀,试过几个,很好
- 7B 模型,至少24G以上
- InteInLM 上海的一家叫书生浦语,话说也很优秀,没用过
- 跨语言可以用 text-emmbedding-ada-002 openAI
- Qwen2-VL-7B-Instruct 多模态视觉模型,大概需要上万张才比较好
# 文本切割
- chunksize 和 overlap来重叠切割(python的nltk库)
- chunksize一般根据文档内容或大小划分,一般设置chunksize=2000,overlap_size=chunksize的10%~20%
- 对于复杂的文本的切割
- NSP任务来进行微调训练(让模型判断A和B两个句子是否有关系)
# 排序
- 检索时过召回一部分文本
- 通过一个排序模型对query和document重新打分排序(from sentence_transformers import CrossEncoder)
- 混合检索(关键字和相似度两种结果进行重新计算,最终得新的排序)涉及技术RRF算法和ES
# 带表格的处理方法
- 将带有表格的PDF转成图片 ( from PIL import Image )
- 识别文档(图片)中的表格(torchvision, transformers, timm),微软对表格理解的模型(microsoft/table-transformer-detection)
- 基于 GPT-4 Vision API 做表格问答
- 用GPT-4 Vision 生成表格(图像)描述,并向量化用于检索
注:如果PDF中有表格,表格中又有图片,很复杂,AI现在处理不了,是否可以用传统的算法来做,例如深度学习,机器学习,自己训练一个模型
# 一些面向RAG的文档解析辅助工具
- RAGFlow 一款基于深度文档理解构建的开源RAG引擎,支撑多种文档
# 向量数据库
- Milvus,支持分布式和混合检索,企业级