 StarRocks的应用
StarRocks的应用
# 为什么要用StarRocks
我们公司是一个小型公司,目前存有三个月的数据,大概在50T左右,采用的技术架构就是Hadoop数仓分层架构。随着业务的发展,公司对数据驱动决策, 对数据价值越来越重视。随着数据量的增长,需求的不断迭代,原有的以 Hadoop 为核心的大数据生态,在性能、实效性、运维难度及灵活性等方面都难 以满足企业的需求,对服务器资源,运维,开发难度越来越高。在一次与朋友探讨大数据,提到StarRocks/Doris,立马引起我的兴趣,查阅了相关资料 后,便启动了StarRocks在业务上的尝试。
# 大数据日常应用场景
对于 T+1 的报表业务,一般是将数据放在 Hive 中定时跑批完成
对于高并发的分析类查询,可以使用 Druid,缓解高峰时期大量用户集中使用给系统带来的查询压力
对于像固定报表业务,可以预先知道了大部分的查询请求,将可以将数据打平成宽表的,放在 ClickHouse 中,充分发挥 ClickHouse 在单表查询的性能优势
对于明细数据的查询或者全文检索的需求,可以使用 Elasticsearch 中,发挥倒排索引的优势
对于多表关联的需求,可以通过 Presto 跨数据源完成多表的 join 操作
但是用StarRocks后,一套解决方案搞定。至少在我们现在100T左右的数据,是非常适合的。同理,再大的数据量也是在这基础上做优化,做更好的设计。
# 我们旧的大数据架构
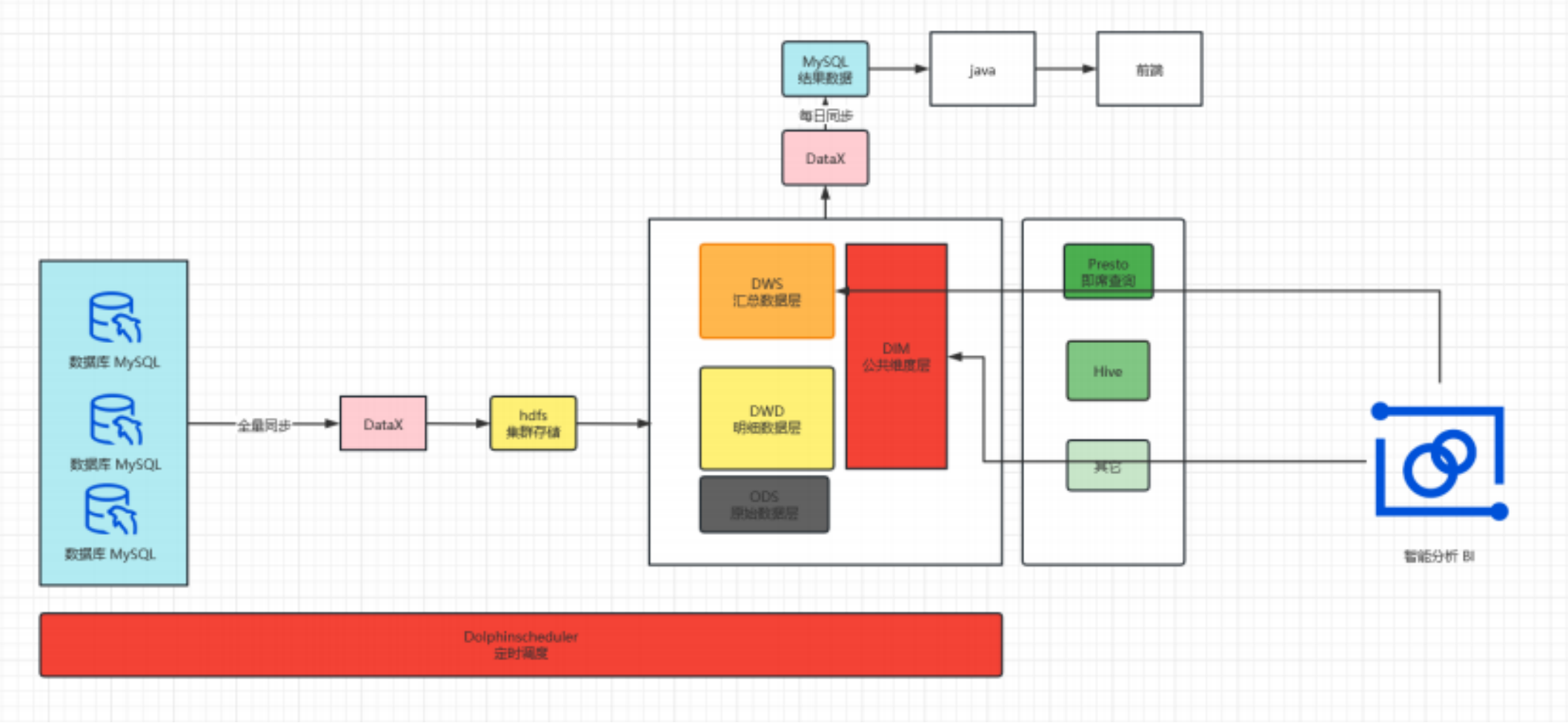
- 离线数仓
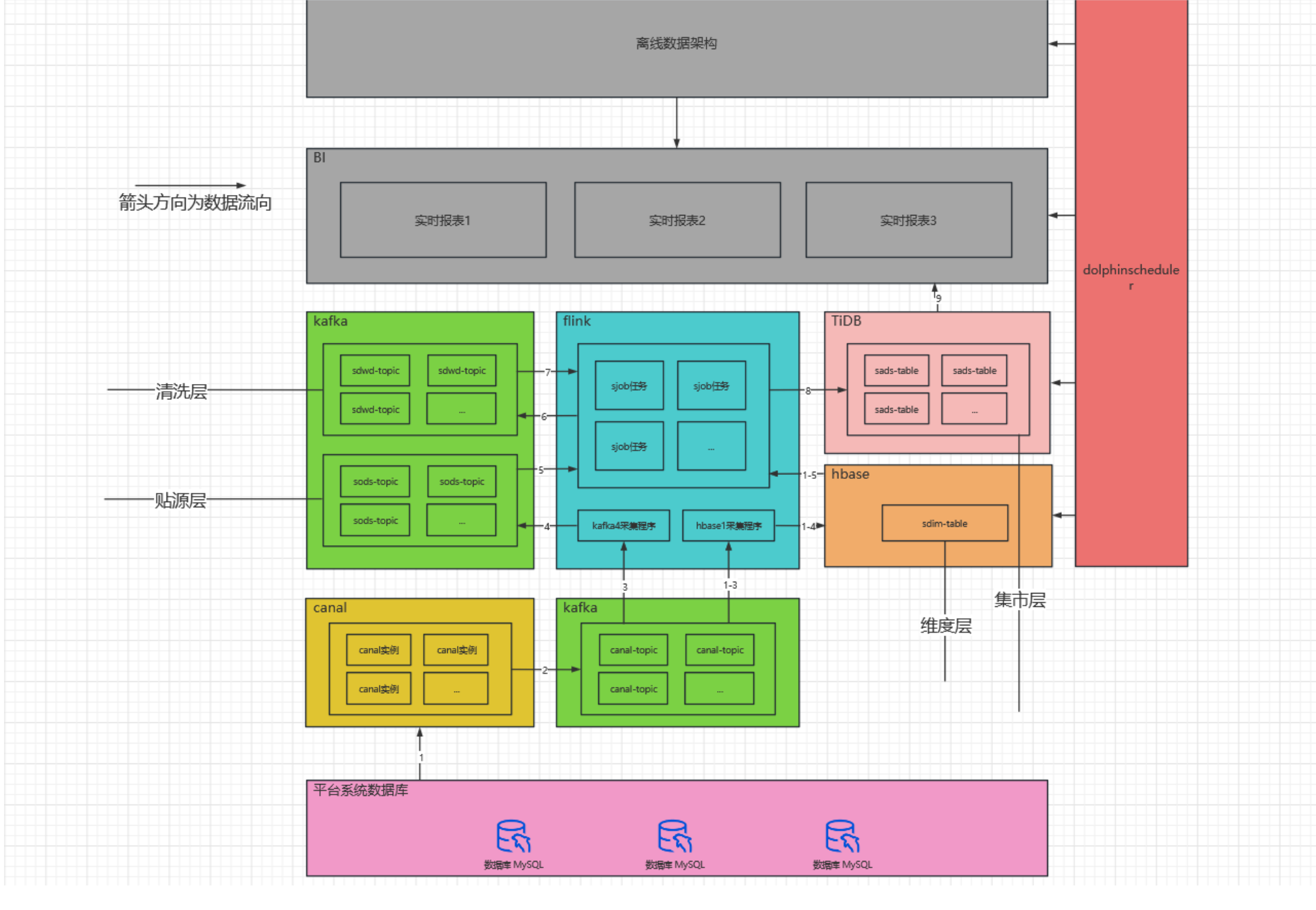
- 实时数仓
- 实时宽表
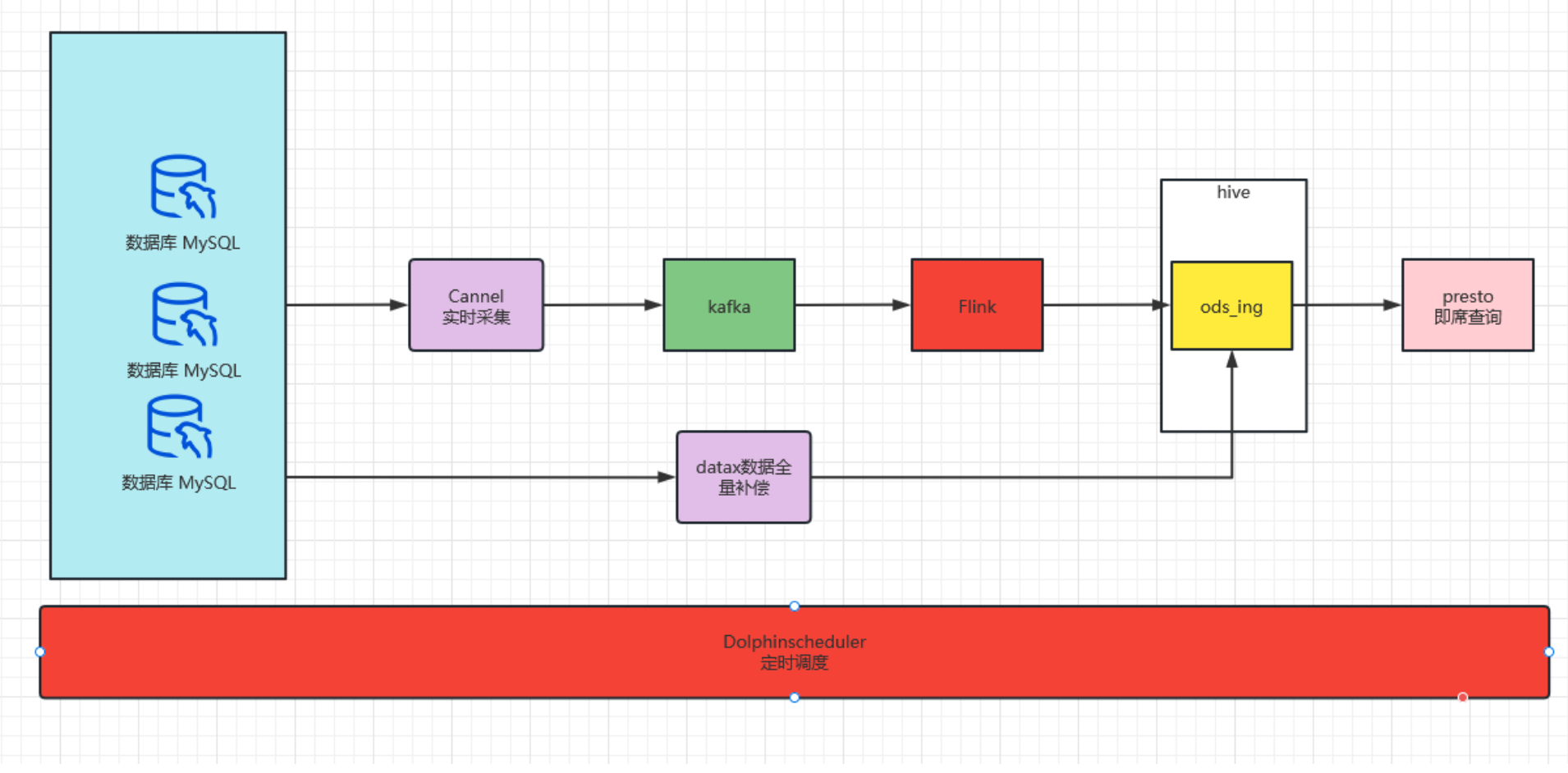
# 旧架构存在的问题
整体集群资源消耗较大、涉及组件多,维护难,排查问题难
当每日数据量瞬时增大时会导致实时数据延迟
presto稳定性和hive兼容性差,不定时的报presto写入hdfs失败
hive on spark 执行效率慢和稳定性差,每日离线数仓加工历史全量数据,因而时不时发生错误导致数据无法正常展示
hive on spark 执行效率低、数仓建模及代码编写不合理导致执行效率低,dws和ads不得不用presto进行计算,presto任务执行完不释放资源,影响实时任务,只能粗暴的杀死进程
实时指标开发不合理,所有任务写在一个jar包,耦合性高
数据建模不合理,中间层存在较大冗余,代码编写复杂和执行效率低,导致数据每日重复计算,浪费集群资源,排查数据问题困难,响应临时需求时间长
presto执行完后,资源不会自动释放,这也是非常大的弊端,应该说presto被我们滥用了
# 新的大数据架构
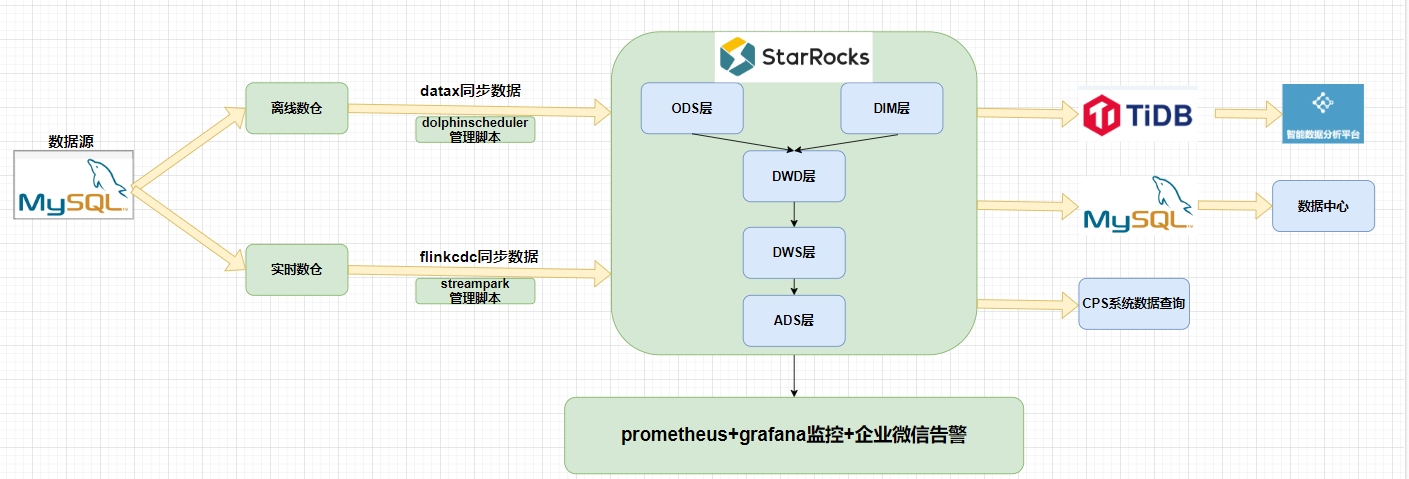
# 使用上新架构后的优势
同步数据分每日全量和每日增量,集群的资源消耗非常低
使用StartRocks后,相比hive+presto计算能力更强,处理数据速度更快
使用flinkcdc能稳定实时同步数据到StartRocks,数据延迟低,准确性高
解决cps端API查询大批量数据慢的问题
增加了prometheus+grafana监控和告警,通过企微通知,能够及时发现问题所在
StartRocks物化视图代替,kafka+hbase+flink,稳定性强,数据延迟低
合理的维度模型和汇总模型,降低执行时间,存储空间和维护成本,更快的排查问题和更小范围的重跑数据,降低新增需求带来的边际成本,提高执行效率已到达更快的响应需求和减少集群成本
整个架构见到了很多,出问题概率小了,排查问题也很快高效