 nebula graph
nebula graph
# Neo4j
一开始我们尝试用neo4j来做个性化推荐,利用其相似性算法,当我们的数据量到了几百万条边的时候,性能瓶颈明显,时不时CPU就飚上去了,然后一上去就下不来。 我们对Neo4j进行优化:
增大neo4j的jvm heap内存
dbms.memory.heap.initial_size;dbms.memory.heap.max_size
cql语句性能排查 1)EXPLAIN + 执行的cql语句 仅仅查看执行计划,不执行语句
(2)PROFILE + 执行的cql语句 运行语句,并全程监督资源使用情况
(3)查看索引创建情况 :schema
- 提升服务器硬件由原来的4c8g,提升到8c16g
优化完后,问题依然存在,也看了相关文档,很多优化方案无法使用
neo4j分为社区版和企业版,开源的是社区版,不支持集群,最大也只能利用4个核,很多优化无法使用,性能太弱了,只能个人学习使用,后面我们尝试使用了nebula graph
# Nebula Graph 架构
Nebula Graph 是一个开源 (Apache 2.0),高性能的分布式图数据库,是一个支持百亿节点,万亿条边,并提供毫秒延迟的图数据库解决方案。它由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。
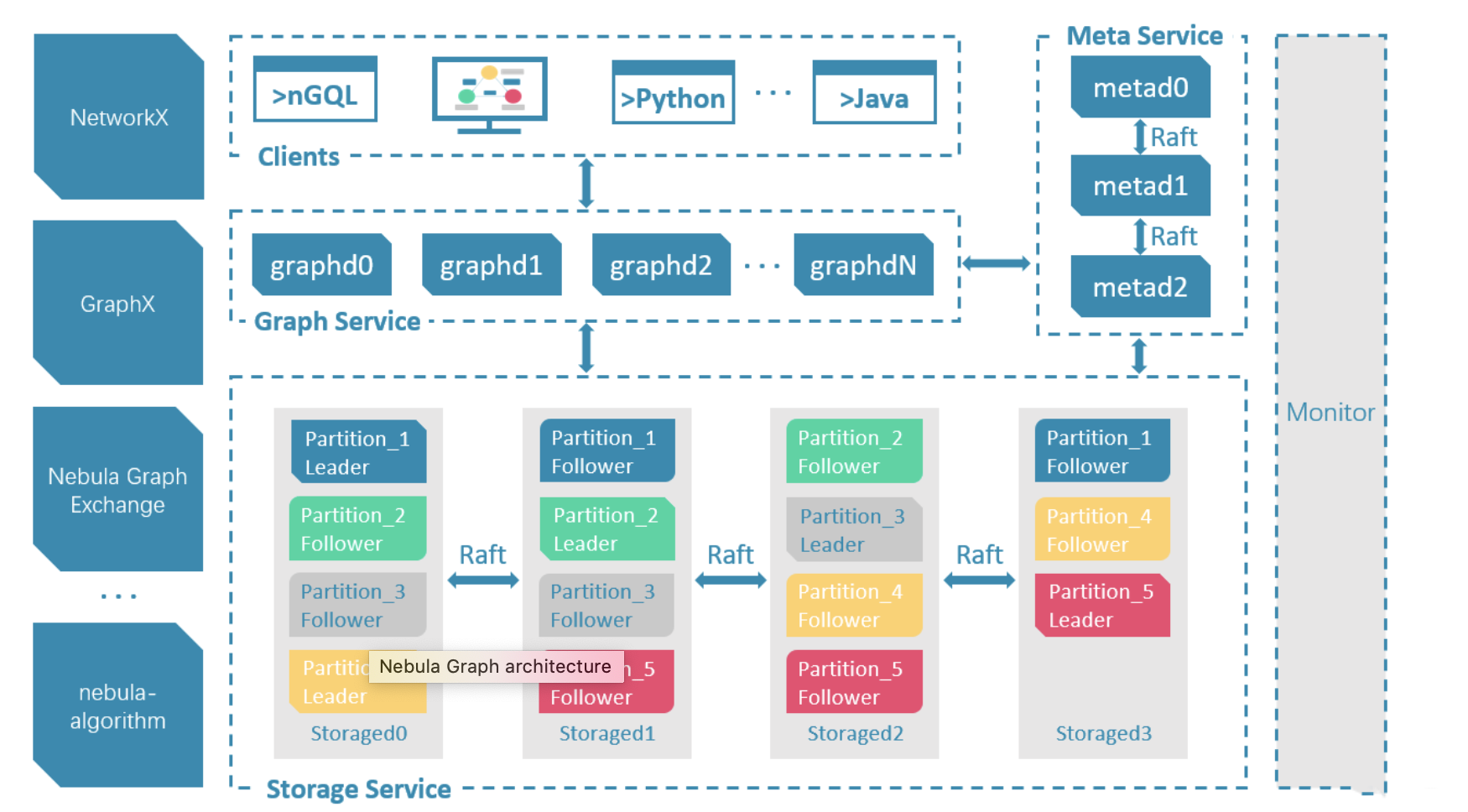
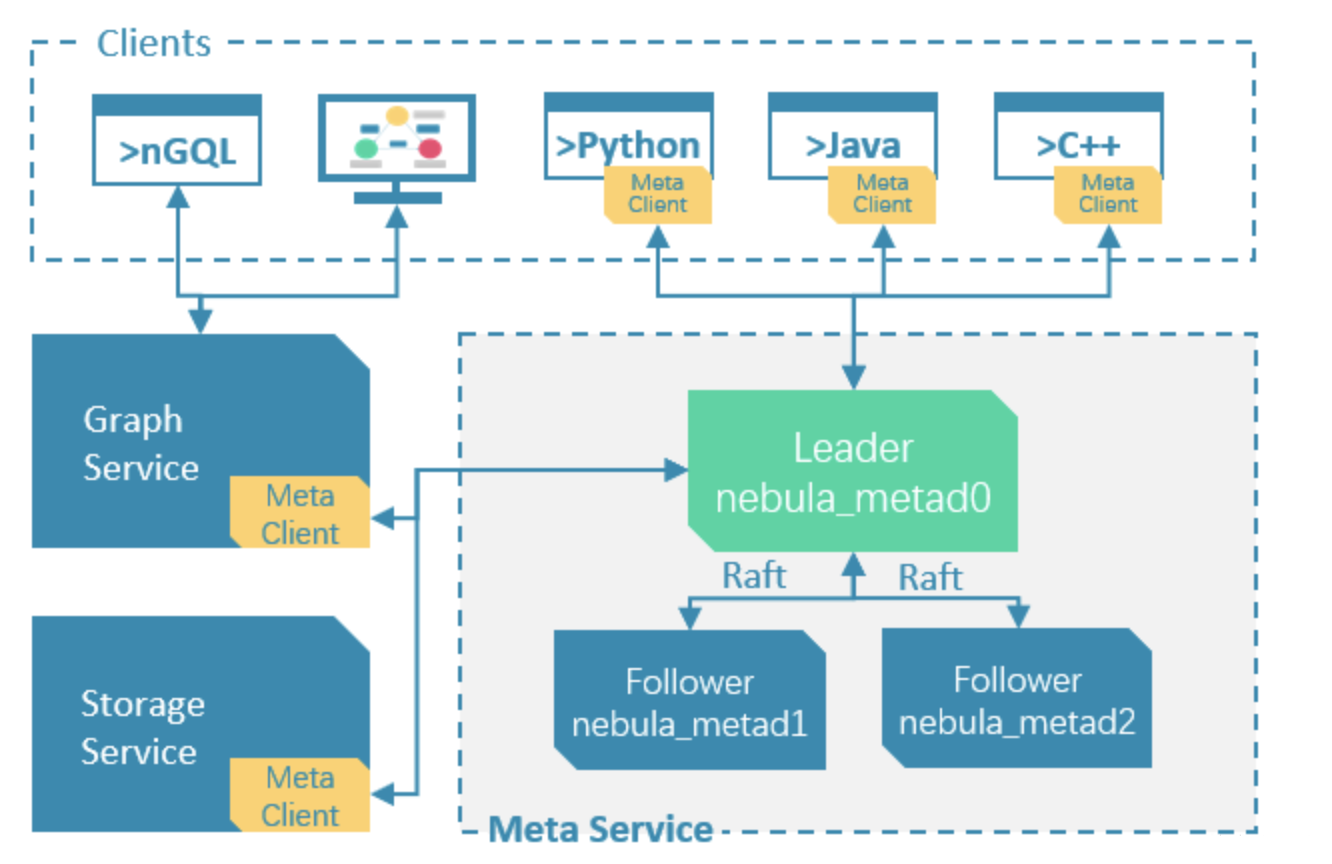
# Meta服务
在 Nebula Graph 架构中,Meta 服务是由 nebula-metad 进程提供的,负责管理
- 管理账号用户信息
- 分片
- 图空间
- schema信息
- TTL信息,提供基于 TTL(Time To Live) 的自动数据回收和空间回收。
- 作业,负责作业的创建、排队、查询和删除
建议至少三副本部署,挂在一台机器上没问题 Meta死透了,影响不能修改元信息,但是插入点边以及查询不受影响 因为storage和graph服务不强依赖Meta,只有启动时会获取信息,只要不修改schema,对storage和graph不影响
# Graph服务和Storage服务
Nebula Graph 采用计算存储分离架构。Graph 服务负责处理计算请求,Storage 服务负责存储数据。它们由不同的进程提供,Graph 服务是由 nebula-graphd 进程提供,Storage 服务是由 nebula-storaged 进程提供。
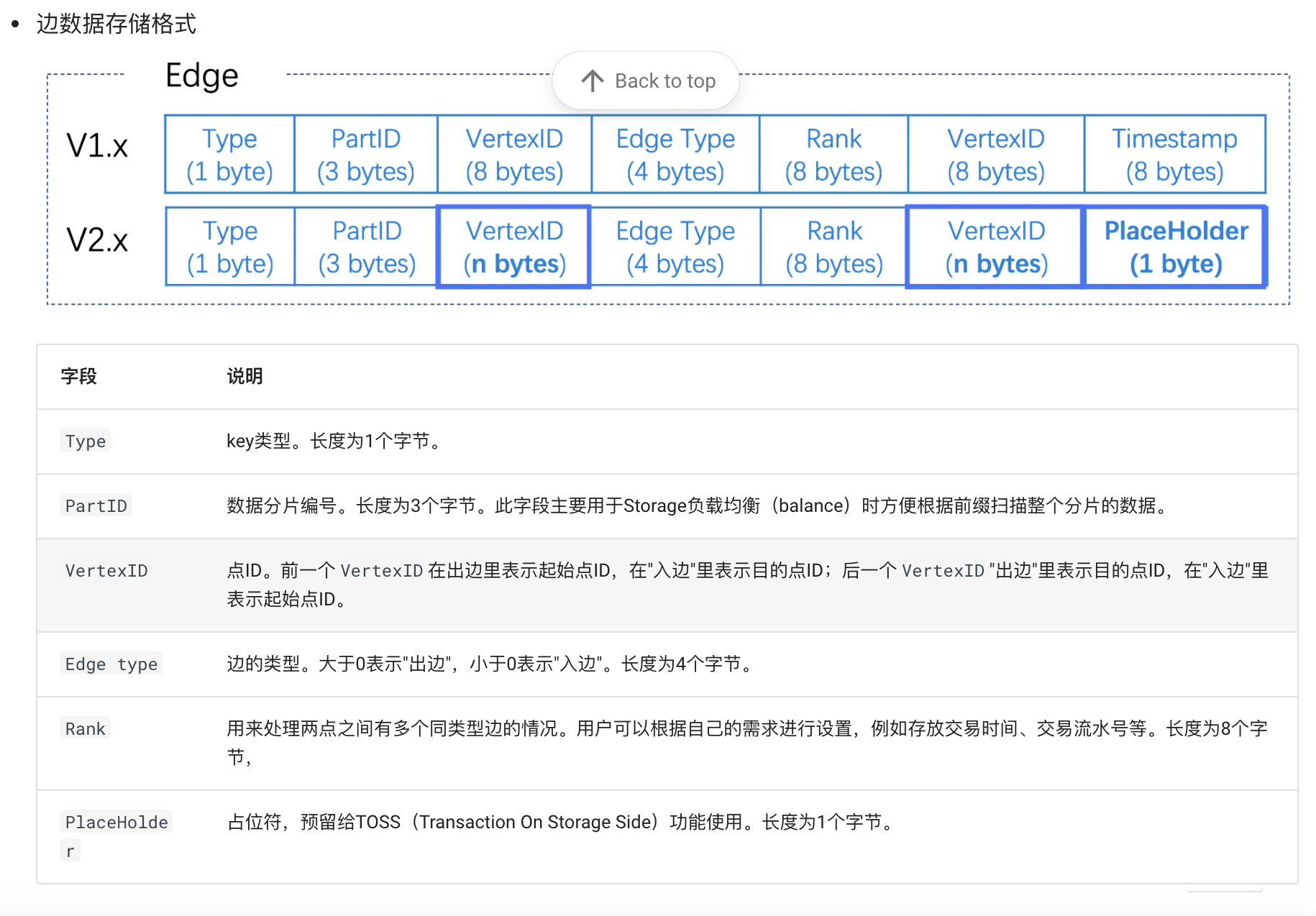
数据存储格式
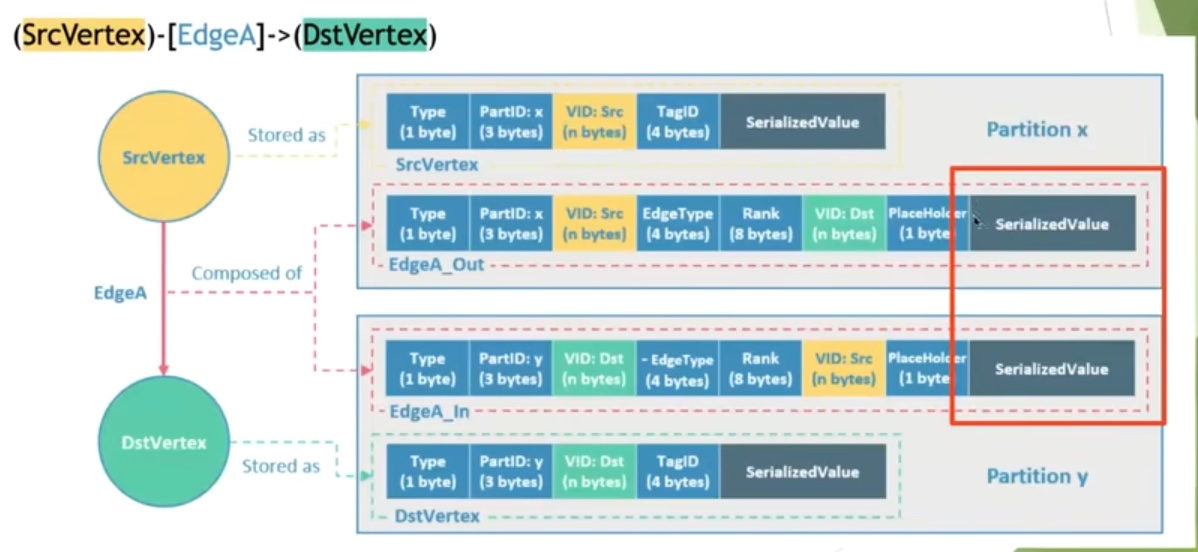
黄色代表出点,绿色代表终点,在nebula Graph 中逻辑上的一条边对应硬盘上的两个键值对(key-value pair), 也就是serializevalue存储两遍(PartitionX, PartitionY),所以在边数量和属性较多时,存储会被放大明显,这样做方便正反面查询。
Graph服务
Graph 服务主要负责处理查询请求,包括解析查询语句、校验语句、生成执行计划以及按照执行计划执行四个大步骤
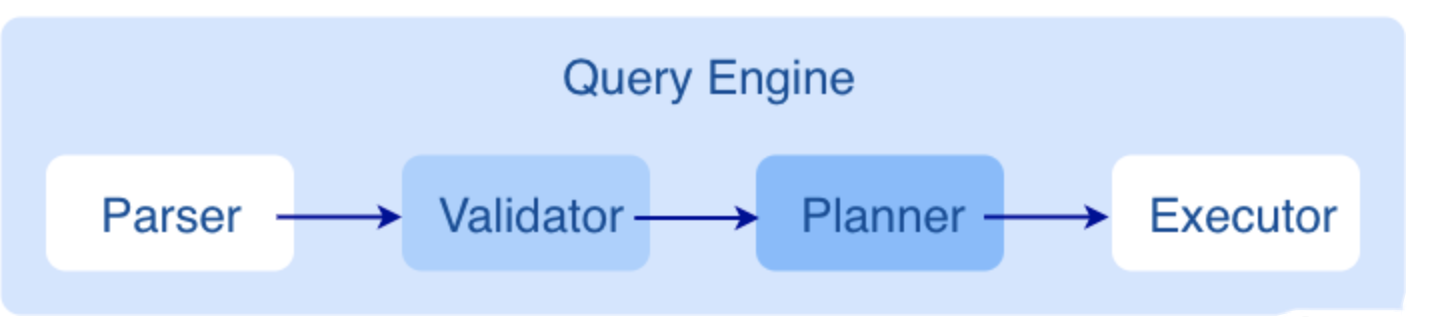
Parser
Parser 模块收到请求后,通过 Flex(词法分析工具)和 Bison(语法分析工具)生成的词法语法解析器,将语句转换为抽象语法树(AST),在语法解析阶段会拦截不符合语法规则的语句。
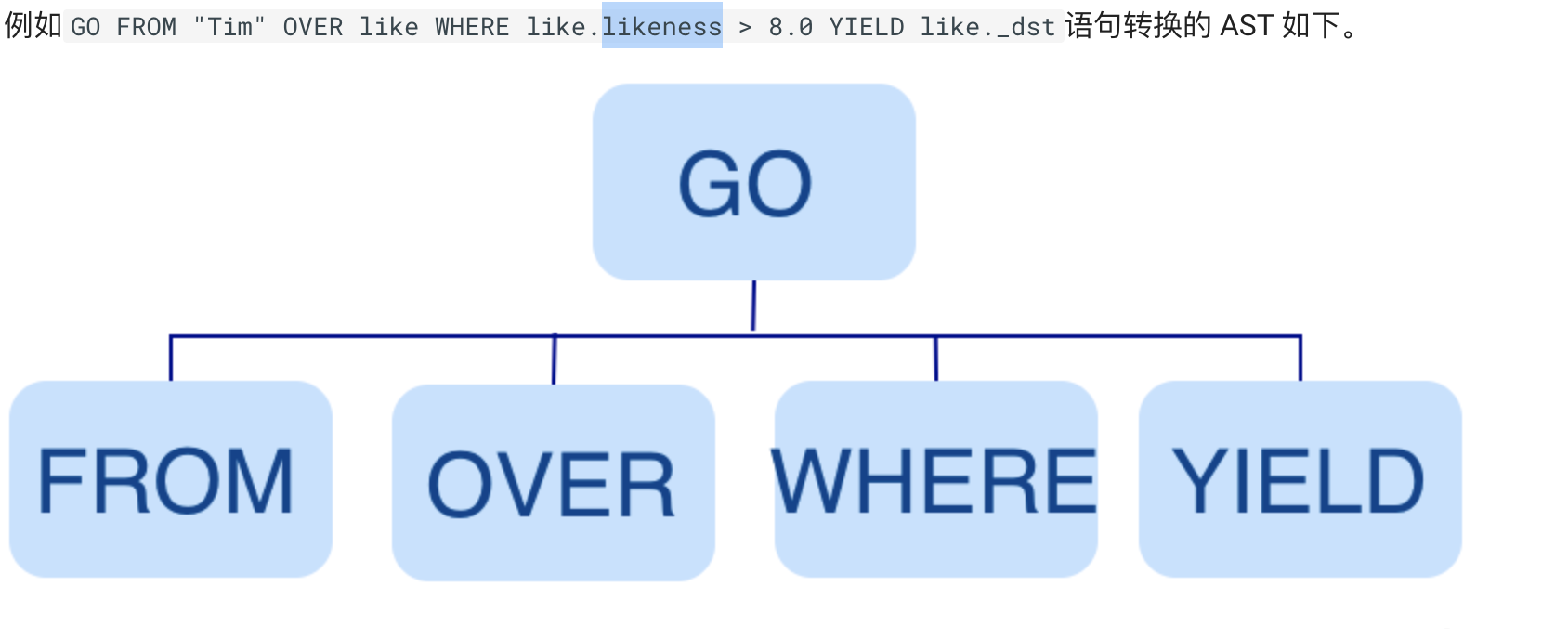
Validator
Validator 模块对生成的 AST 进行语义校验,
1、校验元数据信息
2、校验上下文引用信息
3、校验类型推断
4、校验 * 代表的信息
5、校验输入输出
Planner
如果配置文件 nebula-graphd.conf 中 enable_optimizer 设置为 false,Planner 模块不会优化 Validator 模块生成的执行计划,而是直接交给 Executor 模块执行。
如果配置文件 nebula-graphd.conf中enable_optimizer 设置为 true,Planner 模块会对 Validator 模块生成的执行计划进行优化。如下图所示。
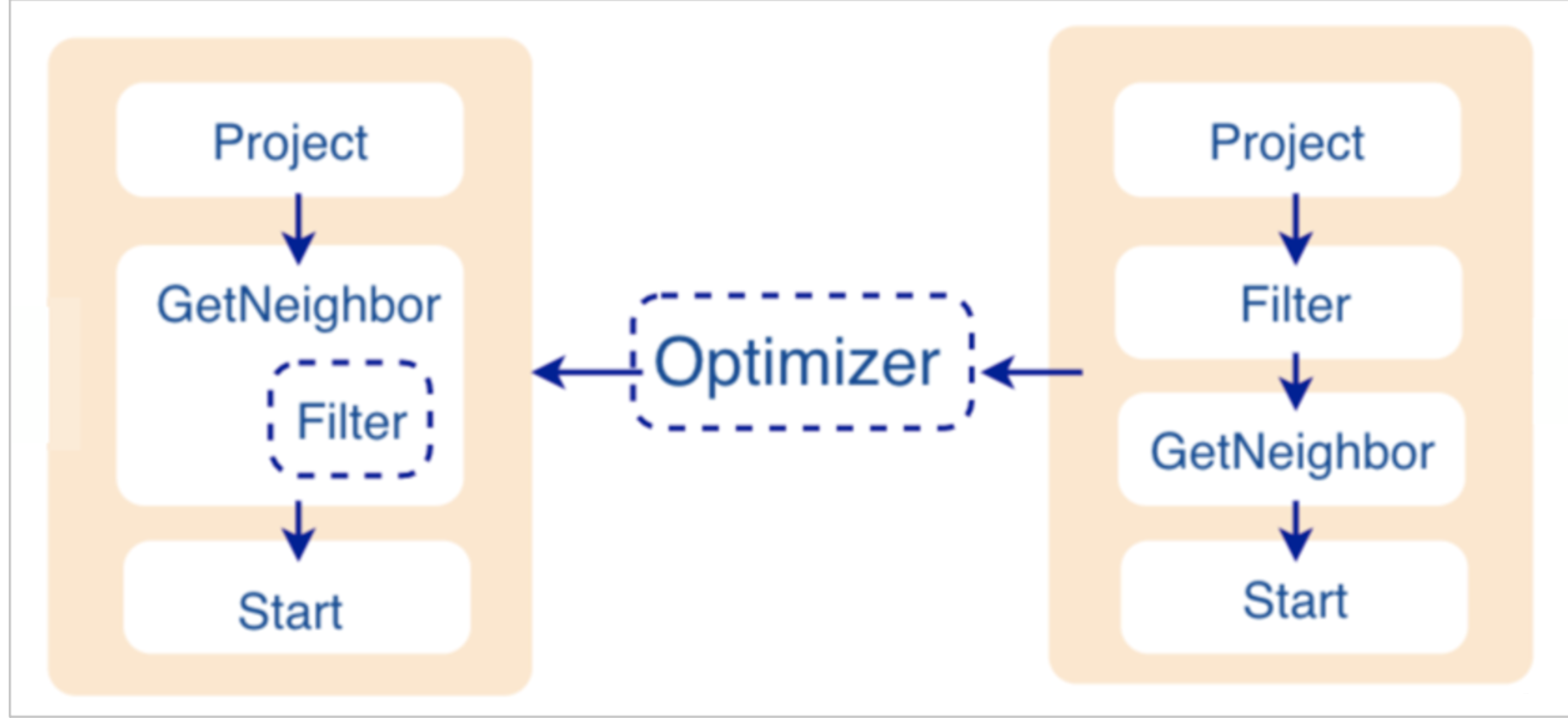
优化过程
Planner 模块目前的优化方式是 RBO(rule-based optimization),即预定义优化规则,然后对 Validator 模块生成的默认执行计划进行优化。新的优化规则 CBO(cost-based optimization)正在开发中。优化代码存储在仓库 nebula-graph 的目录 src/optimizer/ 内。
如上图所示,探索到节点 Filter 时,发现依赖的节点是 GetNeighbor,匹配预先定义的规则,就会将 Filter 融入到 GetNeighbor 中,然后移除节点 Filter,继续匹配下一个规则。在执行阶段,当算子 GetNeighbor 调用 Storage 服务的接口获取一个点的邻边时,Storage 服务内部会直接将不符合条件的边过滤掉,这样可以极大地减少传输的数据量,该优化称为过滤下推。
Executor
Executor 模块包含调度器(Scheduler)和执行器(Executor),通过调度器调度执行计划,让执行器根据执行计划生成对应的执行算子,从叶子节点开始执行,直到根节点结束。如下图所示。
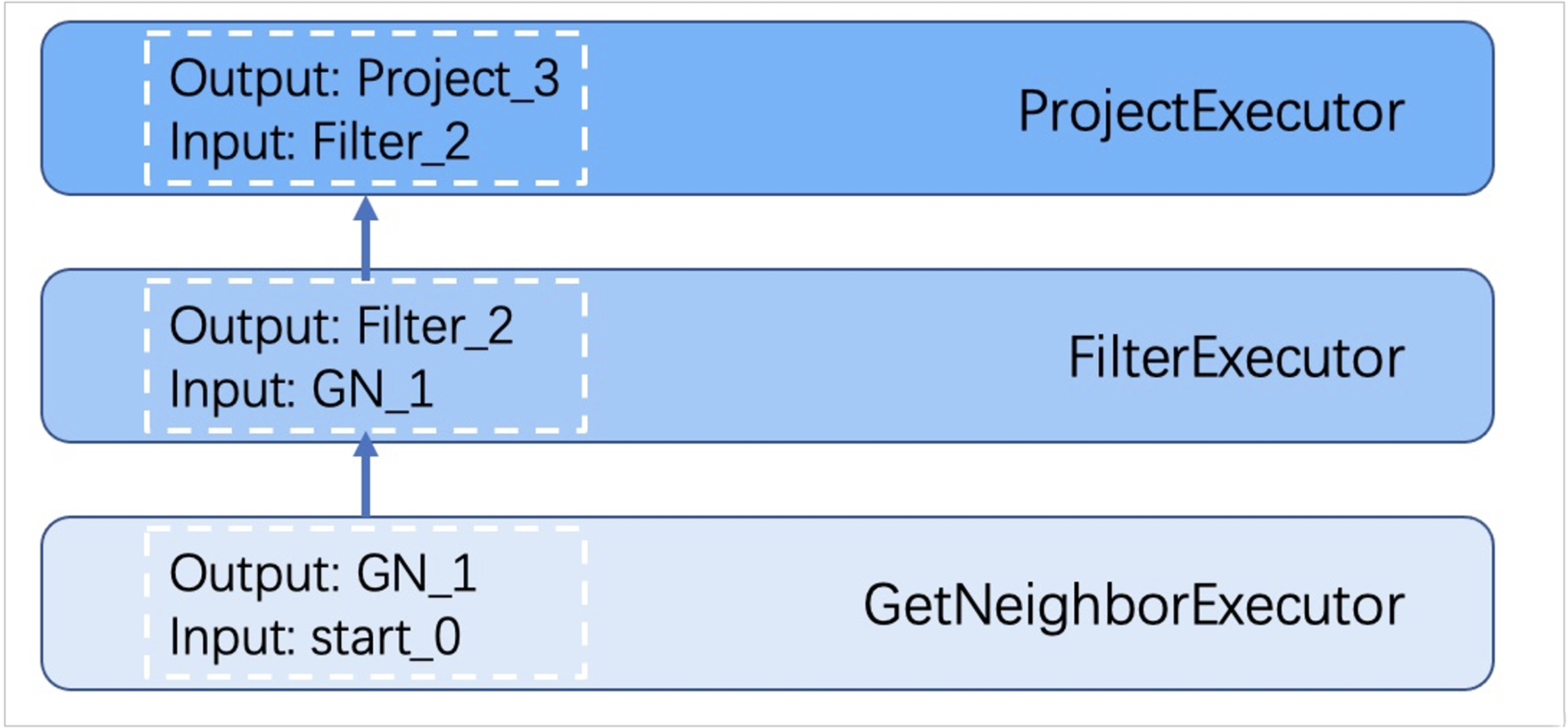
Storage 服务
存储包含两个部分,一个是Meta相关的存储,称为Meta服务。
另一个是具体数据相关的存储,称为Storage服务
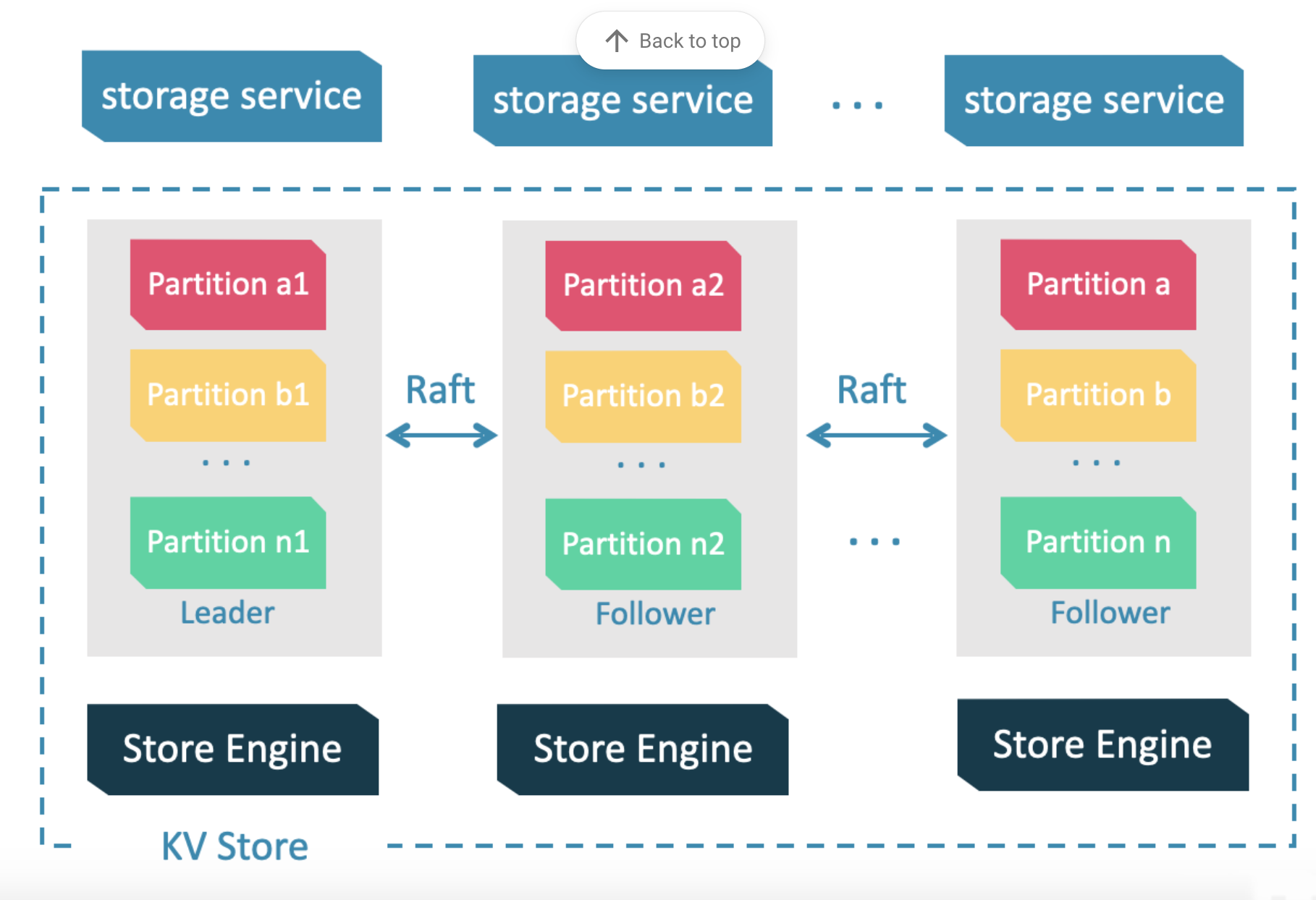
存储引擎部分,基于RocksDb开发的分布式底层存储,用来持久化存储图数据;
Storage interface层
Storage服务的最上层,定义了一系列和图相关的API。API请求会在这一层被翻译成一组针对分片的KV操作,例如:
getNeighbors:查询一批点的出边或者入边,返回边以及对应的属性,并且支持条件过滤。 insert vertex/edge:插入一条点或者边及其属性。 getProps:获取一个点或者一条边的属性。 正是这一层的存在,使得Storage服务变成了真正的图存储,否则Storage服务只是一个KV存储服务。
Consensus层
Storage服务的中间层,实现了Multi Group Raft,保证强一致性和高可用性。
Store Engine层
Storage服务的最底层,是一个单机版本地存储引擎,提供对本地数据的get、put、scan等操作。相关接口存储在KVStore.h和KVEngine.h文件,用户可以根据业务需求定制开发相关的本地存储插件。
图分割 GraphPartition
由于超大规模关系网络的节点数量高达百亿到千亿,而边的数量更会高达万亿,即使仅存储点和边两者也远大于一般服务器的容量。因此需要有方法将图元素切割,并存储在不同逻辑分片 partition 上。Nebula Graph 采用边分割的方式,默认的分片策略为哈希散列,partition 数量为静态设置并不可更改。
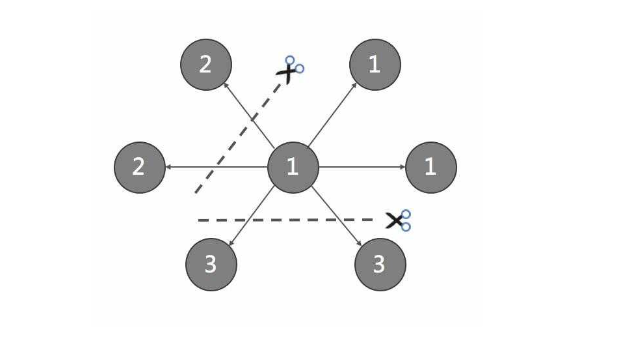
数据存储格式
图存储的主要数据是点和边,Nebula Graph将点和边的信息存储为key,同时将点和边的属性信息存储在value中,以便更高效地使用属性过滤。

通过点属性边属性查找图关系,需要用索引