 Redis数据结构
Redis数据结构
# Redis数据结构
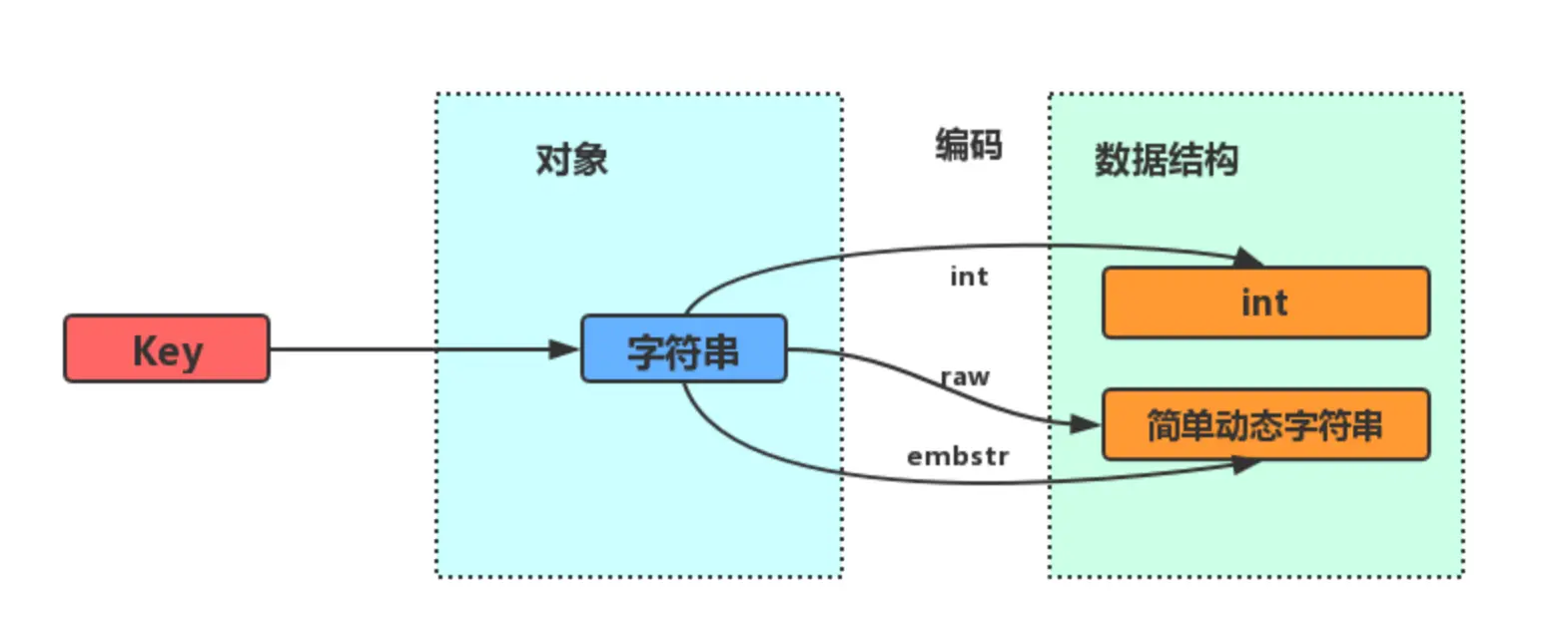
redis底层数据结构使用的是SDS(Simple dynamic string)
# 使用SDS的好处
- 二进制安全的数据结构,所有SDS API都会以处理二进制的方式来处理SDS存放在buf数组里的数据。这也是可以使用redis存视频,图片等二进制文件
- 提供了内存预分配机制,避免了频繁的内存分配
- 兼容C语言的函数库,\0结尾
- 相比C语言字符串,使获取字符串长度时间复杂度降为O(1),C语言需要遍历字符串遇到\0才结束,时间复杂度是0(n)
- 惰性删除机制,字符串缩减后的空间不释放,作为预分配空间保留。
- 节省内存空间
# Redis 底层的数据结构和数据类型对应关系也如下图:
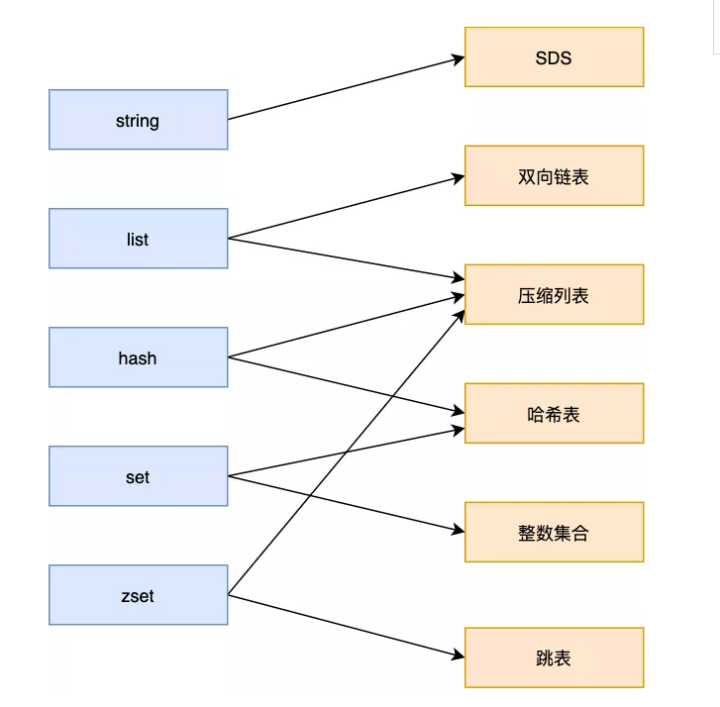
String 数据类型底层数据结构由SDS or long实现;
String的内部存储结构一般是sds(Simple Dynamic String),但是如果一个String类型的value的值是数字,那么Redis内部会把它转成long类型来存储,从而减少内存的使用。
应用场景 String是最简单的数据类型,一般用于复杂的计数功能的缓存:微博数,粉丝数等 还可以用于分布式锁,共享session
List 数据类型底层数据结构由「quicklist 」或「压缩表列表」实现;
list 的实现为一个双向链表,经常被用作队列使用,支持在链表两端进行push和pop操作,时间复杂度为O(1);同时也支持在链表中的任意位置的存取操作,但是需要对list进行遍历,时间复杂度为O(n)。
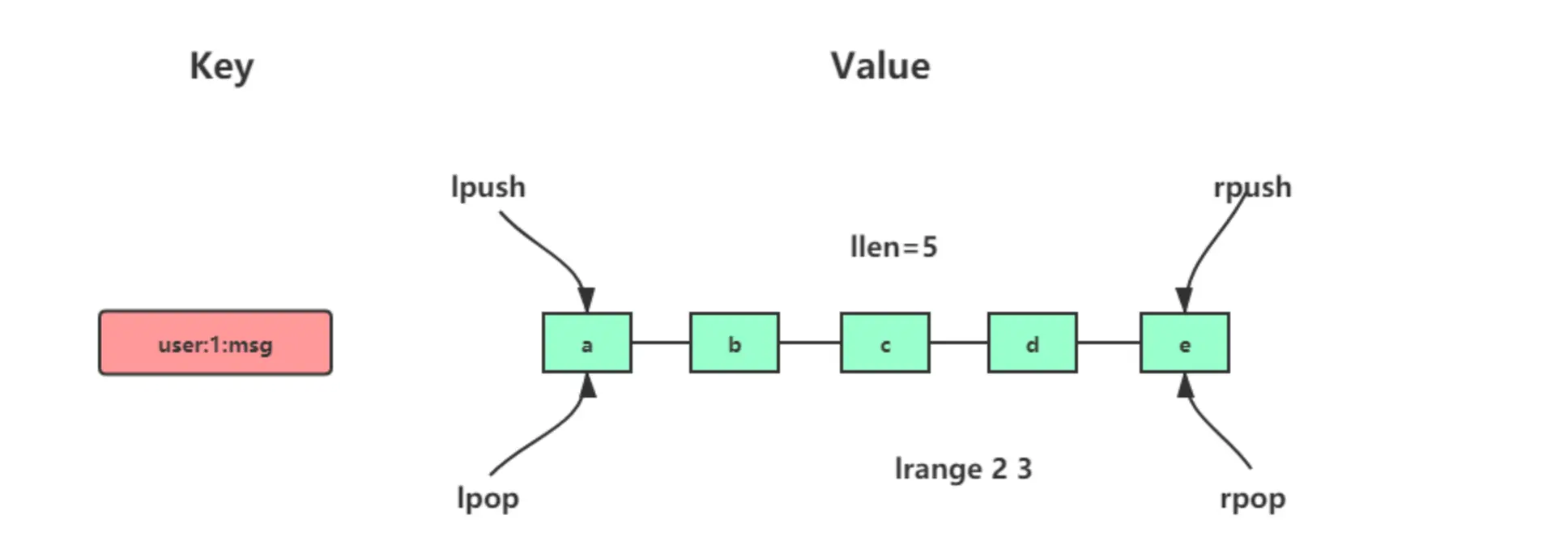
应用场景 比如微博的关注列表,粉丝列表,消息列表等功能都可以用Redis的 list 结构来实现。可以利用lrange命令,做基于redis的分页功能。
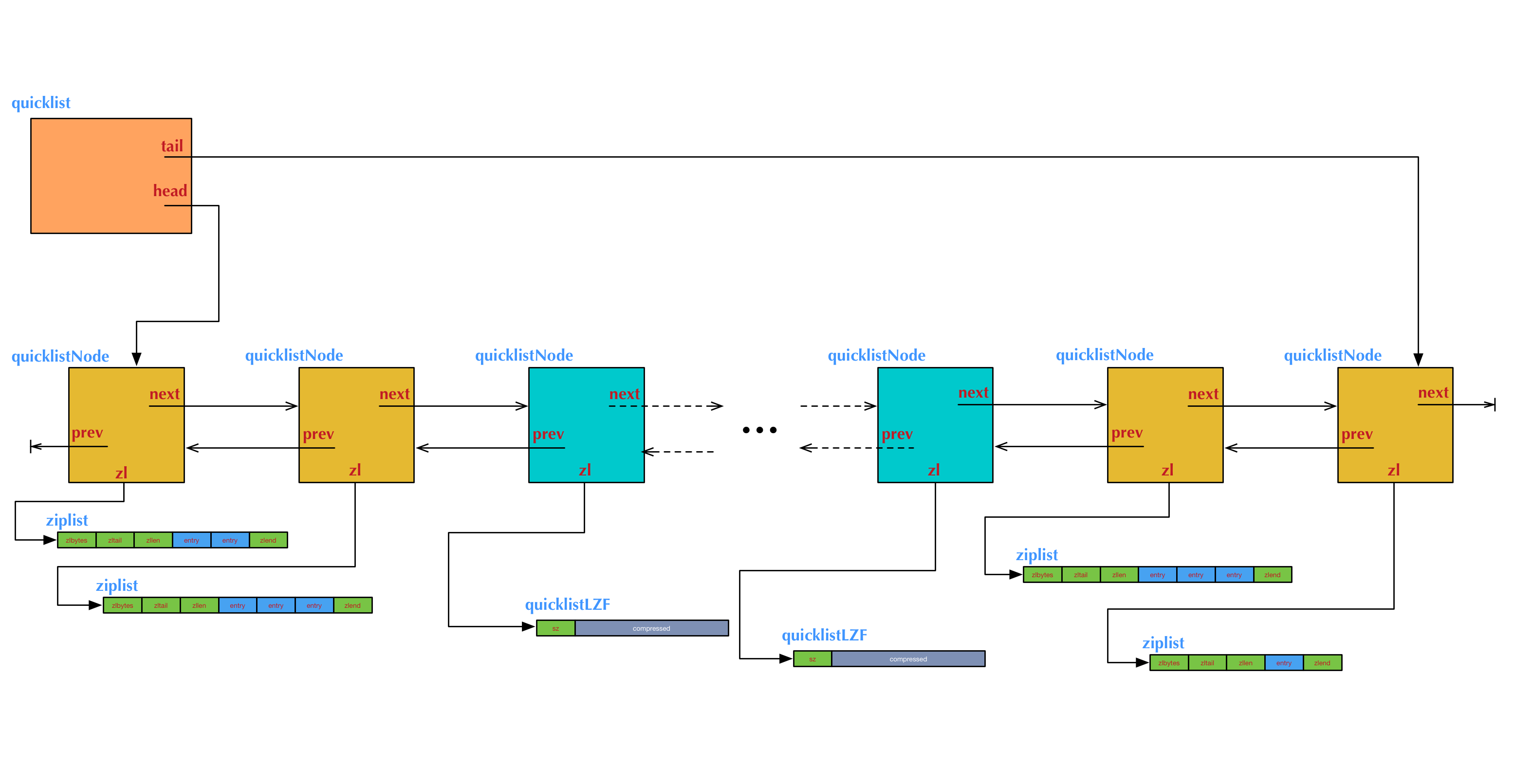
ziplist本来就设计为各个数据项挨在一起组成连续的内存空间,这种结构并不擅长做修改操作。一旦数据发生改动,就会引发内存realloc,可能导致内存拷贝.ziplist采用可变长的编码方式,支持不同类型和大小的数据的存储,更加节省内存,而且数据存储在一片连续的内存空间,读取的效率也非常高 quicklist是一个基于ziplist的双向链表,quicklist的每个节点都是一个ziplist
Hash 数据类型底层数据结构由「压缩列表」或「哈希表」实现; Hash适合用于存储对象,因为一个对象的各个属性,正好对应一个hash结构的各个field,可以方便地操作对象中的某个字段
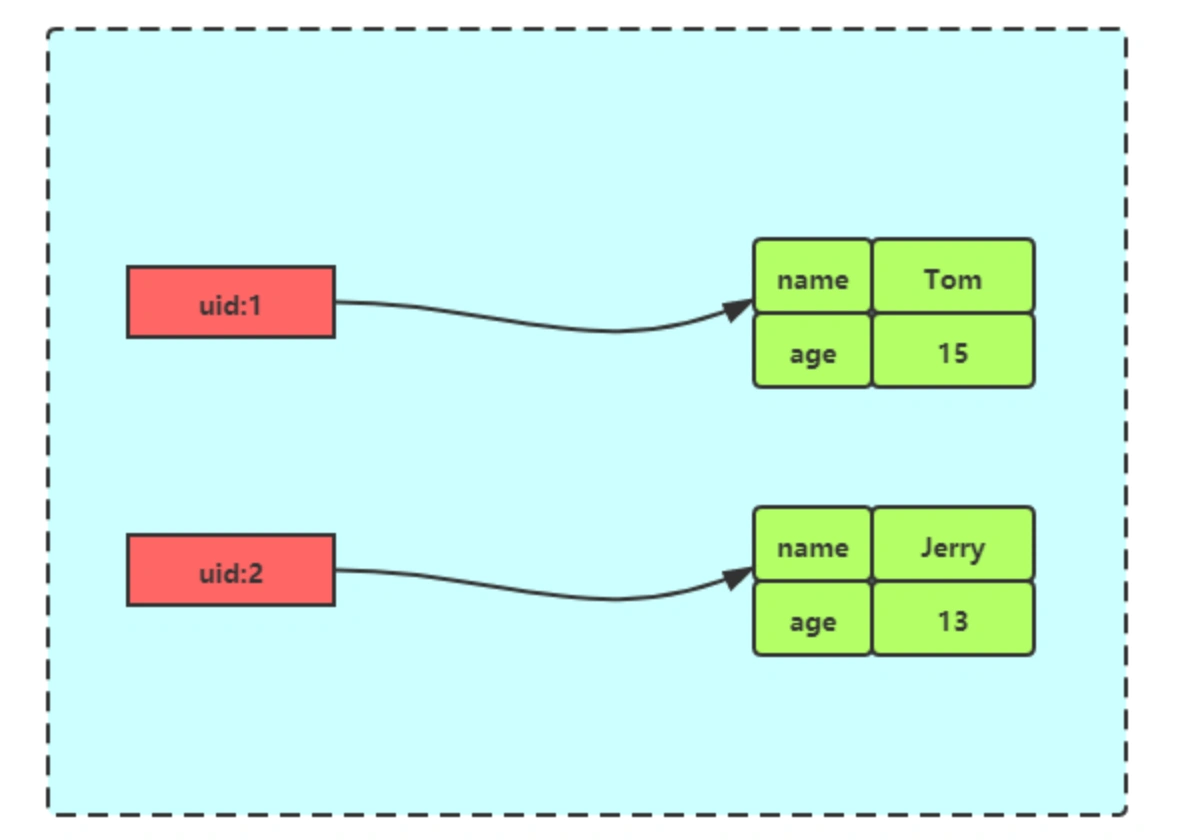
应用场景 Hash 类型的 (key,field, value) 的结构与对象的(对象id, 属性, 值)的结构相似,也可以用来存储对象。一般对象用 String + Json 存储,对象中某些频繁变化的属性可以考虑抽出来用 Hash 类型存储。
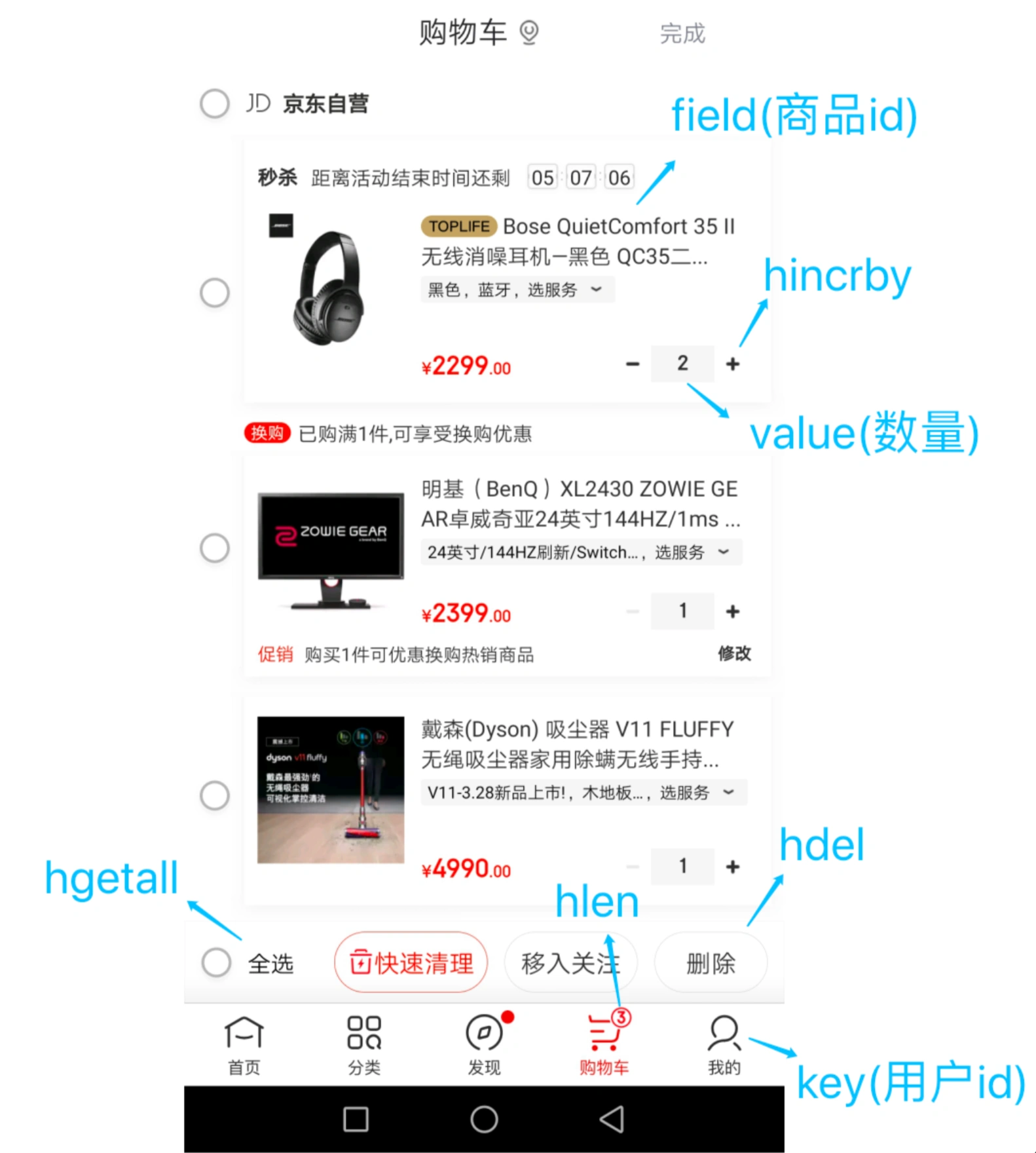
在购物车可以这么用:
Set 数据类型底层数据结构由「哈希表」或「整数集合」实现;
set是一个存放不重复值的无序集合,可做全局去重的功能,提供了判断某个元素是否在set集合内的功能,这个也是list所不能提供的。基于set可以实现交集、并集、差集的操作,计算共同喜好,全部的喜好,自己独有的喜好等功能
当存储的数据同时满足下面这样两个条件的时候,Redis 就采用整数集合intset来实现set这种数据类型:
存储的数据都是整数 存储的数据元素个数小于512个 当不能同时满足这两个条件的时候,Redis 就使用dict来存储集合中的数据
应用场景 点赞
# uid:1 用户对文章 article:1 点赞 > SADD article:1 uid:1 (integer) 1 # uid:2 用户对文章 article:1 点赞 > SADD article:1 uid:2 (integer) 1 # uid:3 用户对文章 article:1 点赞 > SADD article:1 uid:3 (integer) 1 # uid:1 用户取消对文章 article:1 点赞 > SREM article:1 uid:1 (integer) 1 # 获取 article:1 文章所有点赞用户 > SMEMBERS article:1 1) "uid:3" 2) "uid:2" # 获取 article:1 文章的点赞用户数量 > SCARD article:1 (integer) 2 # 判断用户 uid:1 是否对文章 article:1 点赞了 > SISMEMBER article:1 uid:1 (integer) 0 # 返回0说明没点赞,返回1则说明点赞了1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22共同关注
# uid:1 用户关注公众号 id 为 5、6、7、8、9 > SADD uid:1 5 6 7 8 9 (integer) 5 # uid:2 用户关注公众号 id 为 7、8、9、10、11 > SADD uid:2 7 8 9 10 11 (integer) 5 # 获取共同关注 > SINTER uid:1 uid:2 1) "7" 2) "8" 3) "9" # 给 uid:2 推荐 uid:1 关注的公众号 > SDIFF uid:1 uid:2 1) "5" 2) "6" # 验证某个公众号是否同时被 uid:1 或 uid:2 关注 > SISMEMBER uid:1 5 (integer) 1 # 返回0,说明关注了 > SISMEMBER uid:2 5 (integer) 0 # 返回0,说明没关注1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20抽奖活动
>SADD lucky Tom Jerry John Sean Marry Lindy Sary Mark
(integer) 5
# 如果允许重复中奖,可以使用 SRANDMEMBER 命令
# 抽取 1 个一等奖:
> SRANDMEMBER lucky 1
1) "Tom"
# 抽取 2 个二等奖:
> SRANDMEMBER lucky 2
1) "Mark"
2) "Jerry"
# 抽取 3 个三等奖:
> SRANDMEMBER lucky 3
1) "Sary"
2) "Tom"
3) "Jerry"
# 如果不允许重复中奖,可以使用 SPOP 命令
# 抽取一等奖1个
> SPOP lucky 1
1) "Sary"
# 抽取二等奖2个
> SPOP lucky 2
1) "Jerry"
2) "Mark"
# 抽取三等奖3个
> SPOP lucky 3
1) "John"
2) "Sean"
3) "Lindy"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
Zset 数据类型底层数据结构由「压缩列表」或「跳表」实现;
Sorted set 相比 set 多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。另外,sorted set可以用来做延时任务。最后一个应用就是可以做范围查找。
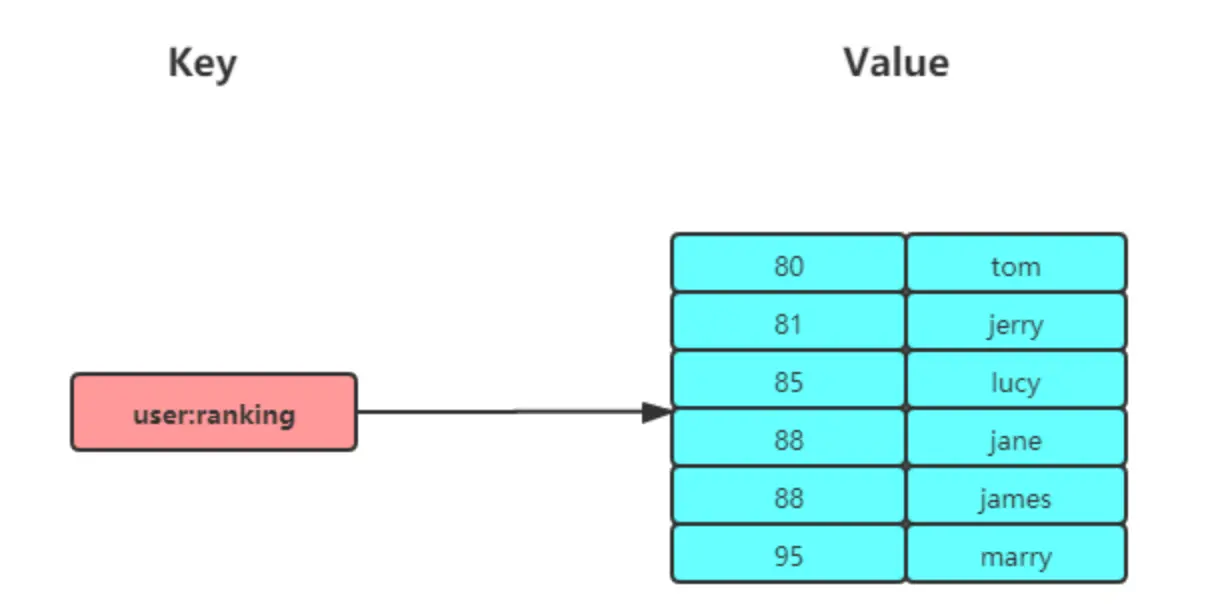
(1)底层实现方式:压缩列表ziplist 或者 zset
当 sorted set 的数据同时满足下面这两个条件的时候,就使用压缩列表ziplist实现sorted set
元素个数要小于 128 个,也就是ziplist数据项小于256个 集合中每个数据大小都小于 64 字节 当不能同时满足这两个条件的时候,Redis 就使用zset来实现sorted set,这个zset包含一个dict + 一个skiplist。dict用来查询数据到分数(score)的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)
跳表是一种可以进行二分查找的有序链表,采用空间换时间的设计思路,跳表在原有的有序链表上面增加了多级索引(例如每两个节点就提取一个节点到上一级),通过索引来实现快速查找。跳表是一种动态数据结构,支持快速的插入、删除、查找操作,时间复杂度都为O(logn),空间复杂度为 O(n)。跳表非常灵活,可以通过改变索引构建策略,有效平衡执行效率和内存消耗
应用场景 成绩的排名榜、游戏积分排行榜、视频播放排名、电商系统中商品的销量排名等
- Bitmap Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。

应用场景 签到统计,判断用户登录态,连续签到用户总数
- GEO Redis GEO 是 Redis 3.2 版本新增的数据类型,主要用于存储地理位置信息,并对存储的信息进行操作。
应用场景 滴滴打车,位置