 RocketMQ基本原理
RocketMQ基本原理
# RocketMQ基本原理
# RocketMQ的事务消息是如何实现的
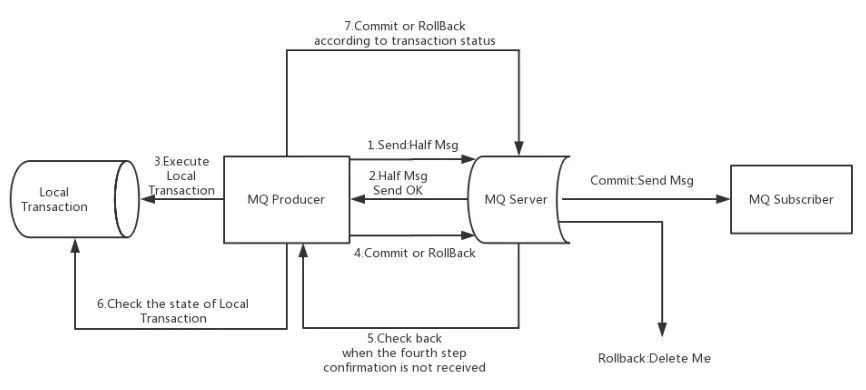
- ⽣产者订单系统先发送⼀条half消息到Broker,half消息对消费者⽽⾔是不可⻅的
- 再创建订单,根据创建订单成功与否,向Broker发送commit或rollback
- 并且⽣产者订单系统还可以提供Broker回调接⼝,当Broker发现⼀段时间half消息没有收到任 何操作命令,则会主动调此接⼝来查询订单是否创建成功
- ⼀旦half消息commit了,消费者库存系统就会来消费,如果消费成功,则消息销毁,分布式事 务成功结束
- 如果消费失败,则根据重试策略进⾏重试,最后还失败则进⼊死信队列,等待进⼀步处理
# 为什么RocketMQ不使⽤Zookeeper作为注册中⼼呢?
根据CAP理论,同时最多只能满⾜两个点,⽽zookeeper满⾜的是CP,也就是说zookeeper并不能保证 服务的可⽤性,zookeeper在进⾏选举的时候,整个选举的时间太⻓,期间整个集群都处于不可⽤的状 态,⽽这对于⼀个注册中⼼来说肯定是不能接受的,作为服务发现来说就应该是为可⽤性⽽设计。 基于性能的考虑,NameServer本身的实现⾮常轻量,⽽且可以通过增加机器的⽅式⽔平扩展,增加集 群的抗压能⼒,⽽zookeeper的写是不可扩展的,⽽zookeeper要解决这个问题只能通过划分领域,划分多个zookeeper集群来解决,⾸先操作起来太复杂,其次这样还是⼜违反了CAP中的A的设计,导致 服务之间是不连通的。 持久化的机制来带的问题,ZooKeeper 的 ZAB 协议对每⼀个写请求,会在每个 ZooKeeper 节点上保 持写⼀个事务⽇志,同时再加上定期的将内存数据镜像(Snapshot)到磁盘来保证数据的⼀致性和持久 性,⽽对于⼀个简单的服务发现的场景来说,这其实没有太⼤的必要,这个实现⽅案太重了。⽽且本身 存储的数据应该是⾼度定制化的。 消息发送应该弱依赖注册中⼼,⽽RocketMQ的设计理念也正是基于此,⽣产者在第⼀次发送消息的时 候从NameServer获取到Broker地址后缓存到本地,如果NameServer整个集群不可⽤,短时间内对于⽣ 产者和消费者并不会产⽣太⼤影响。
# RocketMQ的实现原理
RocketMQ由NameServer注册中⼼集群、Producer⽣产者集群、Consumer消费者集群和若⼲Broker (RocketMQ进程)组成,它的架构原理是这样的: Broker在启动的时候去向所有的NameServer注册,并保持⻓连接,每30s发送⼀次⼼跳 Producer在发送消息的时候从NameServer获取Broker服务器地址,根据负载均衡算法选择⼀台服务器 来发送消息 Conusmer消费消息的时候同样从NameServer获取Broker地址,然后主动拉取消息来消费
# RocketMQ为什么速度快
因为使⽤了顺序存储、Page Cache和异步刷盘。我们在写⼊commitlog的时候是顺序写⼊的,这样⽐ 随机写⼊的性能就会提⾼很多,写⼊commitlog的时候并不是直接写⼊磁盘,⽽是先写⼊操作系统的 PageCache,最后由操作系统异步将缓存中的数据刷到磁盘